搬运自之前的小脑洞小想法啦
又是个小脑洞
最近有个比赛要统计一下各组信息,信息来自Word版的申请表。
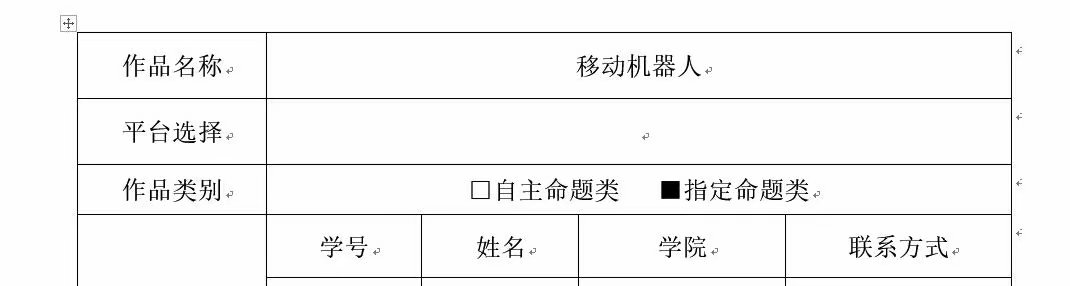
考虑到Word要一个一个打开,再复制粘贴。
简单重复,太难受了8,不如干脆py一下,写个小程序来弄吧。
大致思路
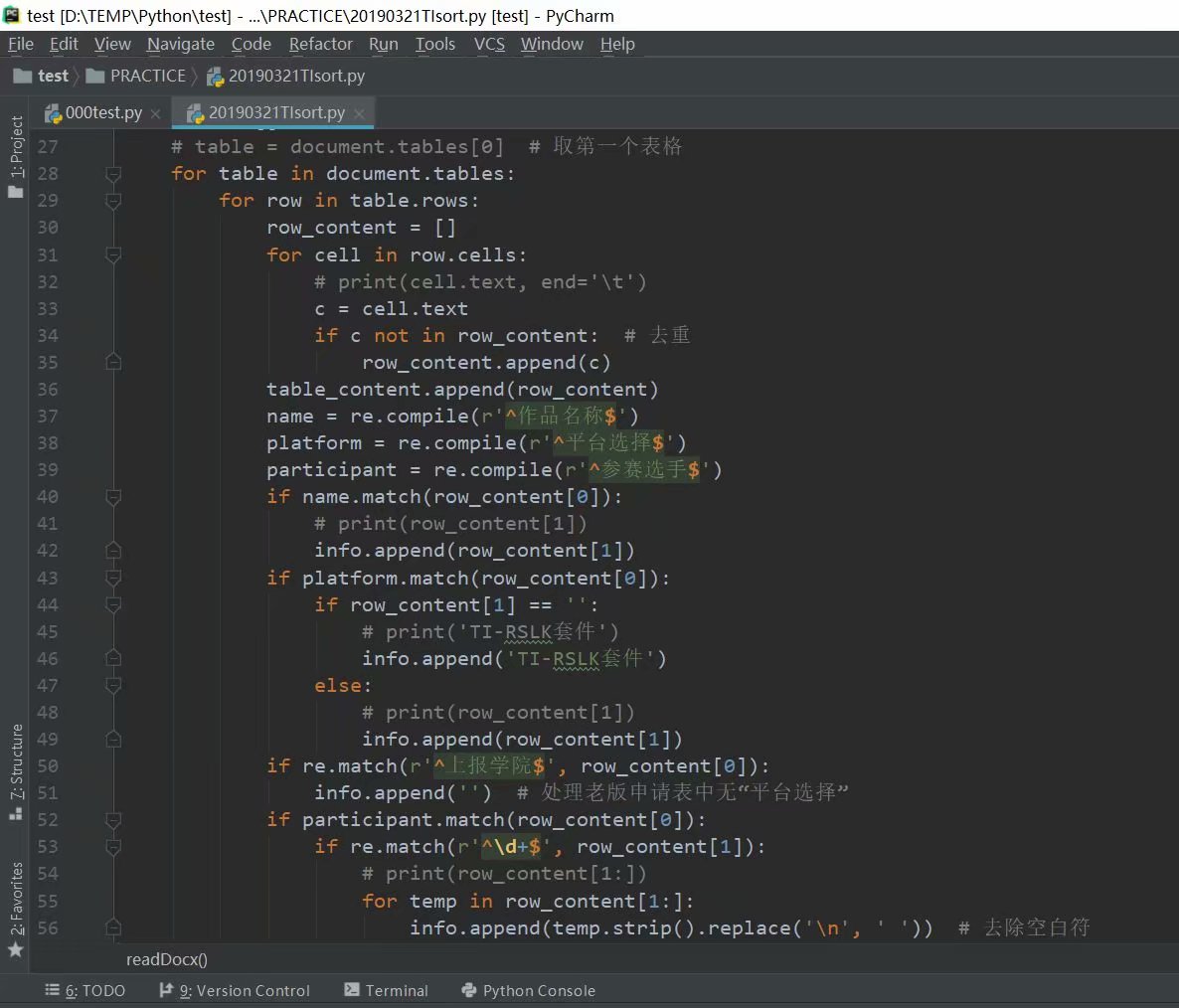
一查发现.docx是以类似xml格式来存放信息的,刚开始思路就想直接解压.docx,从中解析文件然后暴力匹配。。
而后发现有个**第三方库python-docx**,于是乎不想造轮子了,直接拿来用吧。
然而并没有那么简单,合并的单元格变成独立重复的内容,加个去重吧。
提取信息
文字都解析出来了,接下来,来点简单的正则匹配,单独拿个文件来试试,没毛病,挺好的。
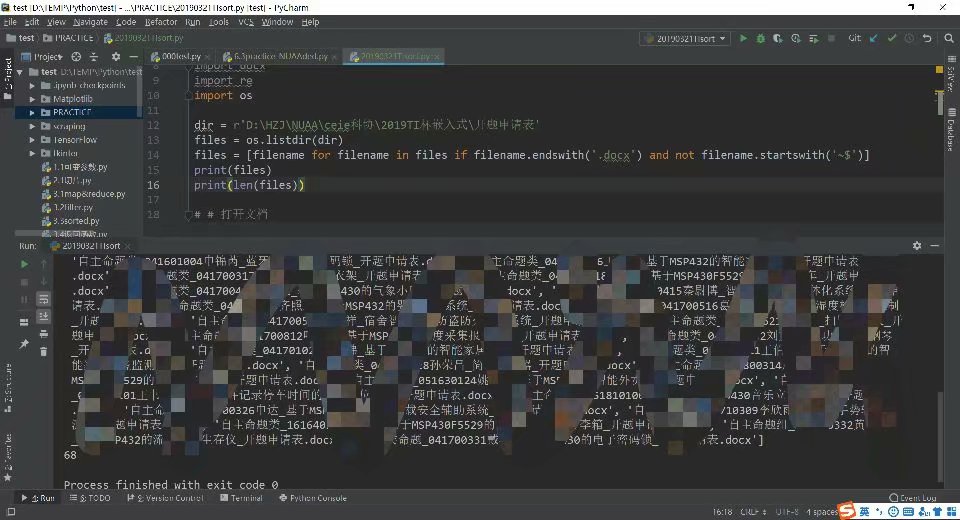
批量读取
遍历文件夹下所有文件,筛选.docx且排除临时文件,噫少了俩。
原来还有.doc格式的,另存为.docx *(docx库只支持.docx)*。
依次读取每个文件,拼接string列表,得到所需信息。
写入文件
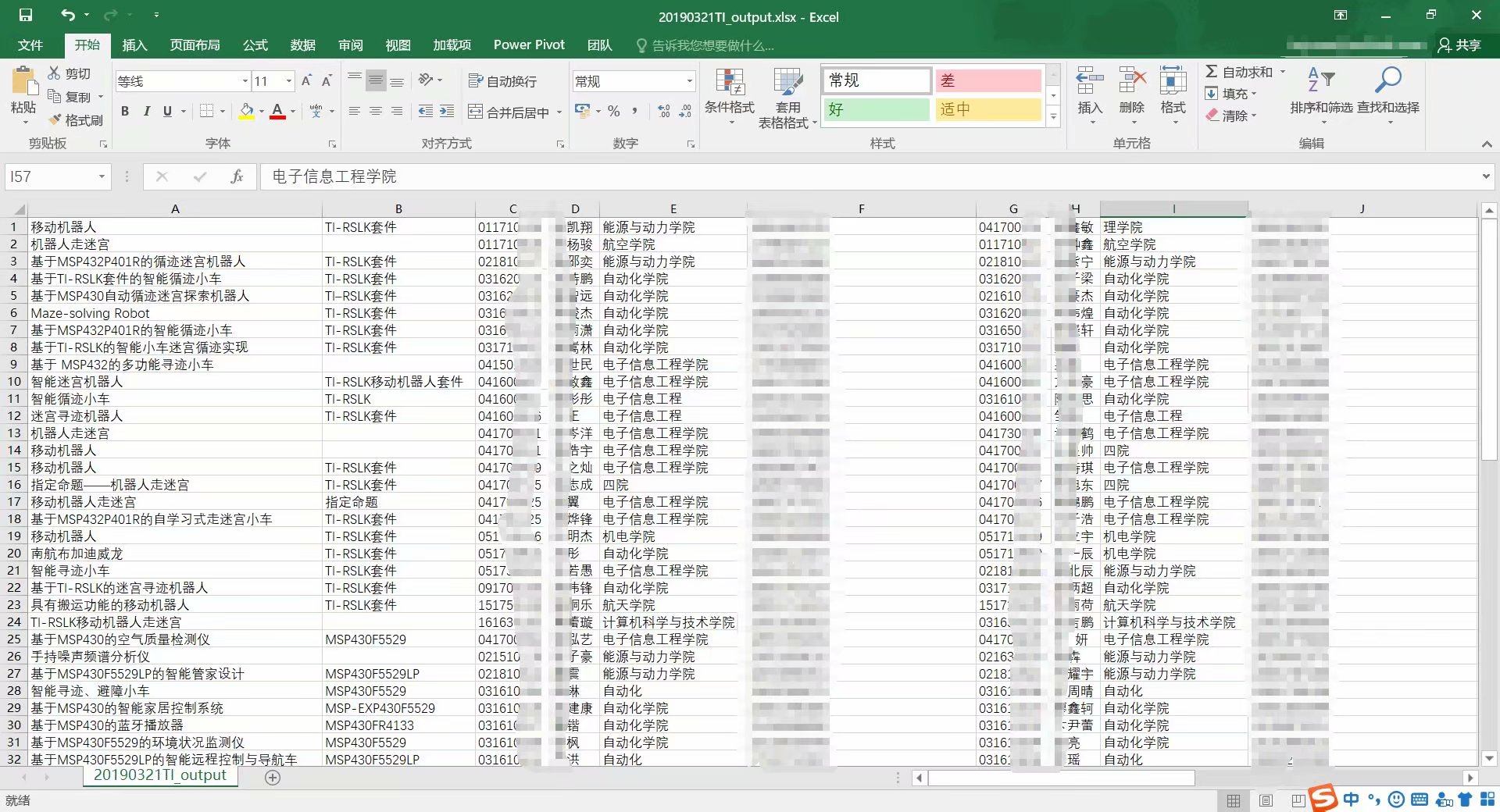
将infolist按照.csv的格式写入文件。
其实可以调用第三方库来实现的。
debug
实际情况还是挺复杂的,比如表格哪里没填空缺了,或者哪个里面多加几个分隔符什么的,还是出了不少bug,于是继续完善程序,加入相应的处理呗!
生产环境真复杂
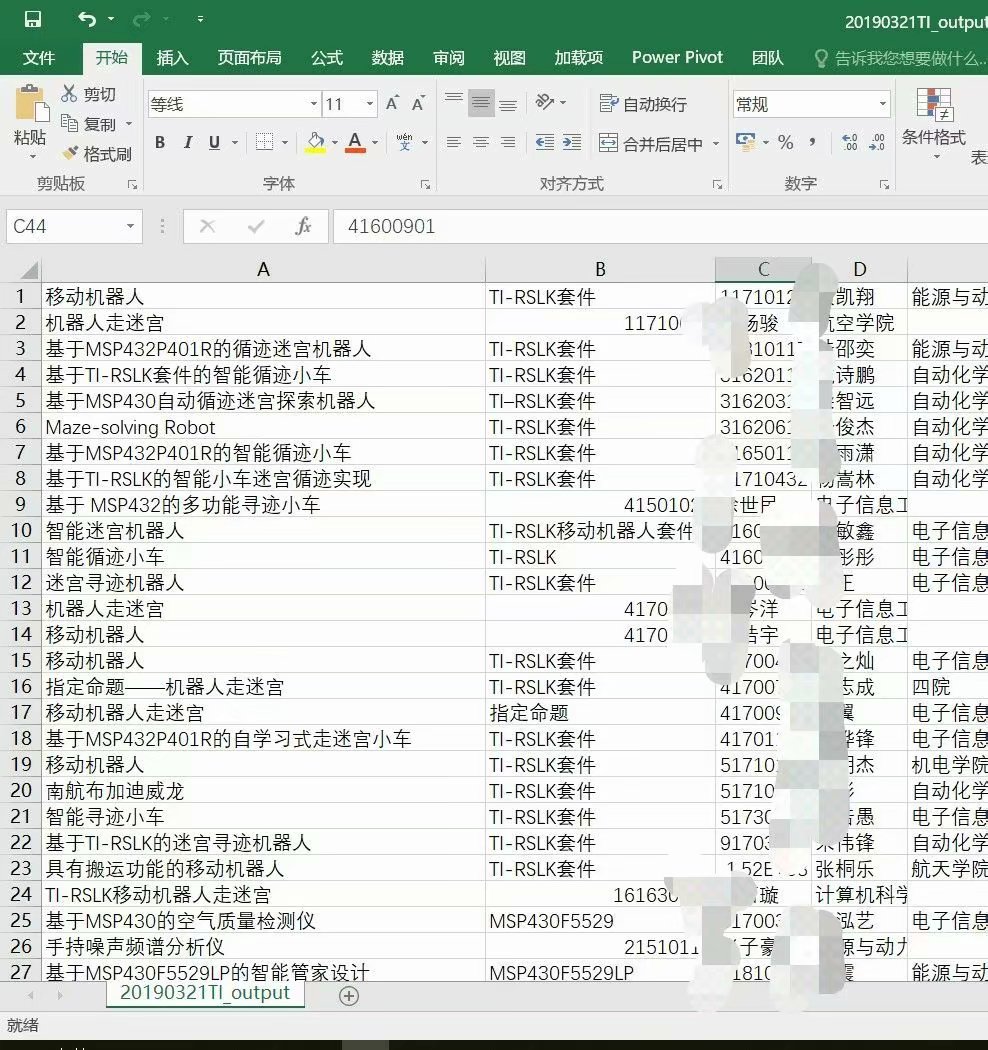
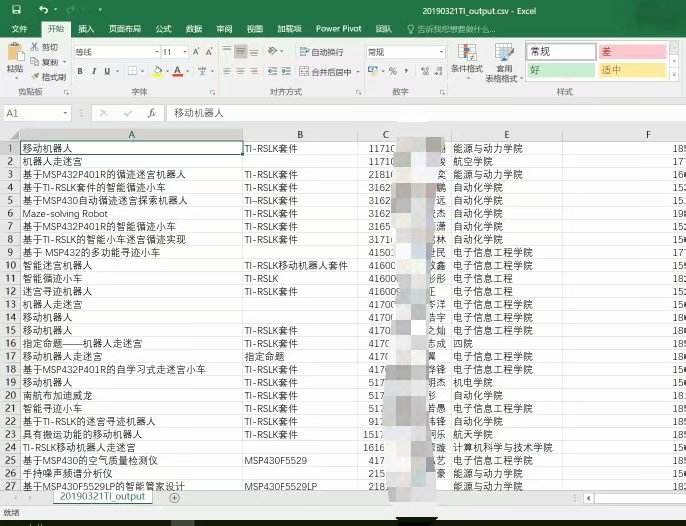
如果用Excel打开.csv,发现学号前的0自动丢失,还是觉得不爽emmm (程序猿的自我修养
又查了查资料,新建.xlsx,从文本导入到Excel,设置好属性。
几好,完事!
于是乎边查资料边debug边改代码 花了一个多两个小时
估计几个人同时手动做早都做完了
(其实早就想过用py读取Excel了,但是一直还没试过,这次就先拿py读取Word试试水吧


