前言
前不久在服务器上装好了Huginn(详见这里:基于Docker搭建Huginn)。
这几天折腾了一下,尝试着用它来爬点东西玩一下(bushi
想了一下,平时会关注教务的通知,每次都要访问教务网站,虽然说也不是很麻烦,但我想要一个自动推送的工具。或者说,不需要我主动去看有没有新通知,而是有新通知公告了就直接推过来。(类似于Webhook? 😃
说到这个,其实之前在 RSSHub 上看到过一个,不过现在好像失效了。考虑到目前没有折腾 RSSHub 的打算,干脆就用 Huginn 自己弄一个好了。
说干就干了啦。
哦对了,最终的效果大概这样——
通知的爬取
与其说专门打造一个教务通知公告的爬取,不如说记录一下 Huginn 的基本使用方法。
说实话,Huginn 的资料真的少,感觉国内都没有多少介绍这个的,于是遇到了不少问题经常不知道怎么办emmm。
一些小介绍
打开你喜欢的浏览器,进入 Huginn(默认为 127.0.0.1:3000),最上方有如下几个选项。
其中Agents就是你的一个个小兵,他们可以互相协作,按照流水线依次完成各自的使命。
Scenarios 就是这些小兵的集合,或者说是某种场景,官方描述是
Scenarios are named groups of Agents. Scenarios allow you to organize your agents, and to import and export sets of Agents to share.
比如说你有A、B、C三个Agent,他们共同完成一个任务,你就可以把他们集合起来作为一个Scenario。
Events 是小兵们收集来的信息。
Credentials 用来记录一些常量,或者说是环境变量。
Credentials are used to store values used by many Agents. Examples might include “twitter_consumer_secret”, “user_full_name”, or “user_birthday”.
在使用时,就可以像 {% credential Meow_API %} 这样来引用,其中 Meow_API 在 Credentials 中进行定义。
大体思路
Huginn 里有很多种 Agent,这里用到的可以说是最常用的 Website Agent 和 Post Agent 。
更多的可以参考官方 Wiki 的介绍,在这里。
这个项目的思路就是
- 访问教务网站,爬取通知公告栏的标题及链接
- 根据得到的链接,访问相应网址,获得通知具体内容
- 将得到的信息打包,根据 Server Chan 和 Telegram Bot API 的格式发送即可
创建获取信息的 Agent
Crawler_AAO #1 Get Notice URLs
选择 Website Agent,界面如下:
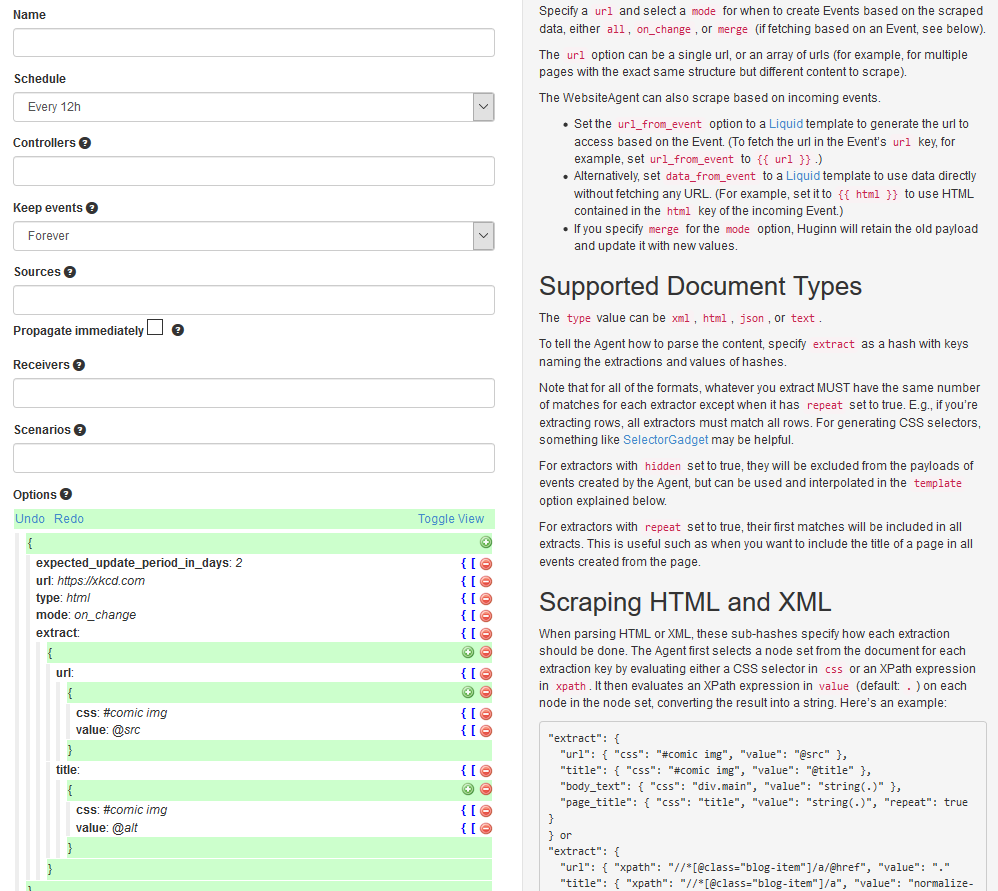
Name自己取个喜欢的名字。
Schedule可以指定运行的周期。如果列表里没有合适的选项的话,可以选择Never,再另外创建一个Scheduler Agent,以cron格式自己写一个,然后在Controllers里指向这个Scheduler Agent。
Keep events可以定义获得Events后保留的时间,过期后自动会删除之前的Events。每次爬取后,获得新的数据才作为一个event,否则不会触发一个新的event,可以说在一定程度上起到了去重的作用。(当然如果还有重复的话,可以后面再加一个De-duplication Agent)
如果数据量过大的话最好不要设成Forever。但是要确保在下一个 Agent 能够在 Event 过期之前获取到数据。
Sources就是上一个Agent,Receivers就是下一个Agent。勾选Propagate immediately的话,上一个Agent获取到数据后则立即执行这个Agent,否则会间隔一分钟再执行。(开启会加重CPU负担)
Scenarios就是那个Agents的集合啦。
Options里是具体的配置,是JSON的格式,可以参考右边的提示来进行设置。
怎么说好呢,其实简单的参数右边是有了,但是实际配置的时候还是有不少问题。看官方文档吧emmm
https://huginnio.herokuapp.com/agents 这里有关于Agents各自API的详细介绍。
下面是options的具体介绍。
Website Agent可以爬取来自url/url_from_event/data_from_event的信息。
type
可以xml, html, json, or text。相应的类型有各自的介绍,这里是HTML网页,就用html好了。
mode
可以是all, on_change, or merge。If you specify merge for the mode option, Huginn will retain the old payload and update it with new values.
即如果选择merge,则会与之前的信息合并,这个在获取教务通知的具体内容时会用到,之后不再赘述。这里只需要在出现新通知的时候触发,所以用on_change。
extract
extract里就是要解析的内容,可以用a CSS selector in css or an XPath expression in xpath. (如果type里选text则可以用regexp正则匹配,然而如果要html提取后再正则匹配就需要再来一个Agent,感觉有点蠢emmm如果有更好的办法欢迎来和我交流一下哈)
要注意的是:这个解析的内容是根据url浏览后直接获得的页面,没有加载文本之外的任何内容,没有经过JavaScript渲染等等。或者说就是你
F12在Network里看到的页面加载出来的document或xhr之类得到的response。(这个是在利用 Huginn 爬取其他网站的时候发现的)如果需要爬取JavaScript加载的网页,可以使用 Phantom Js Cloud Agent,这个需要在PhantomJs Cloud申请一个API,有一定的免费额度。这个Agent会返回页面的相应信息,还可以具体设置输出JSON、截图等等。
extract里以JSON格式写要解析的对象,后面就会返回 相应名字作为Key,相应的值作为Value 的JSON结果。
CSS可以这样找↓,直接复制CSS路径,再进行缩略处理。
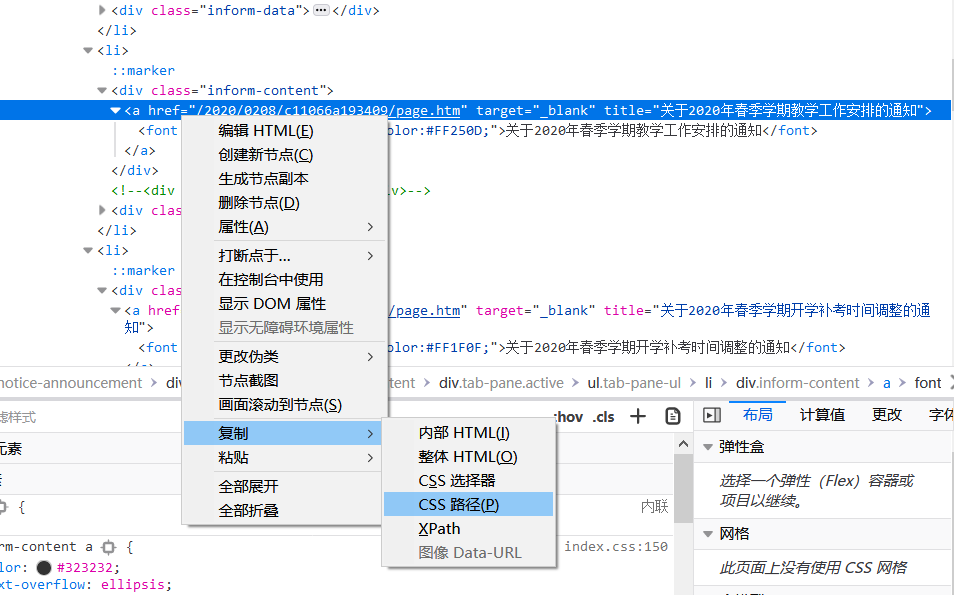
比如这里复制出来是
html body div.container-fluid div.main-content.clearfix div.left-content div.notice-announcement div#index_notice_content.tab-content div.tab-pane.active ul.tab-pane-ul li div.inform-content a然后处理 css path。
原始路径过长,删去不带 . 或 # 的节点(节点间以空格“ ”分割),并删去每个节点在 . 或 #前的第一个标签,得到:
.container-fluid .main-content.clearfix .left-content .notice-announcement #index_notice_content.tab-content .tab-pane.active .tab-pane-ul .inform-content a前半部分对节点定位用处不大,继续缩略,于是得到
.tab-pane.active .tab-pane-ul .inform-content a非常规情况处理:
a. 有些路径中的节点带空格,如
<div class="packery-item article">,路径中的空格由.代替,截取为.packery-item.articleb. 当抓取多种 css path 规则时,用逗号
,分割"css": ".focus-title .current a , .stress h2 a",
value用来提取标签中的属性,可以利用XPath functions。(中文介绍)
Xpath Functions是可以进行嵌套来用的(套娃(x
这里用了 @href来提取链接,用string(.)来提取这个css路径下的字符串,用 normalize-space函数来去除多余的空格。得到的JSON表达式如下。
"extract": {
"url": {
"css": ".tab-pane.active .tab-pane-ul .inform-content a",
"value": "@href"
},
"title": {
"css": ".tab-pane.active .tab-pane-ul .inform-content a",
"value": "normalize-space(string(.))"
}
}template
除了上面这些,还可以设置User Agent,以及一个用**Liquid模板语言编写的模板template**等等。
Liquid markup language. Safe, customer facing template language for flexible web apps.
Liquid官方仓库:https://github.com/Shopify/liquid。这里有关于Liquid语法的中文介绍:https://liquid.bootcss.com/。
Liquid也是可以嵌套的,利用管道 | 可以将处理后的结果送到下一个filter。
除了Liquid自带的filter,Huginn还提供了一些自己的用法,详见官方文档 Formatting Events using Liquid。

在这里,由于得到的 href 是相对地址(如 /2020/0208/c11066a193409/page.htm),为了得到绝对地址,在template中利用 {{ url | to_uri: _response_.url }} 进行处理。
(别说了,这几天找遍了XPath function和Liquid用法)
设好之后可以点击Dry Run来试试,看看运行的结果,再做进一步的修改。
于是最终得到的Crawler_AAO #1 Get Notice URLs Options 如下。
{
"expected_update_period_in_days": "2",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0",
"url": "http://aao.nuaa.edu.cn/",
"type": "html",
"mode": "on_change",
"extract": {
"url": {
"css": ".tab-pane.active .tab-pane-ul .inform-content a",
"value": "@href"
},
"title": {
"css": ".tab-pane.active .tab-pane-ul .inform-content a",
"value": "normalize-space(string(.))"
},
"time": {
"css": ".tab-pane.active .tab-pane-ul .inform-data",
"value": "normalize-space(.)"
}
},
"template": {
"url": "{{ url | to_uri: _response_.url }}"
}
}创建获取内容的 Agent
Crawler_AAO #2 Get Notice Contents
一样是Website Agent。
Sources选择第一步创建的Agent,即 Crawler_AAO #1 Get Notice URLs。
Options中的url就来自第一个Agent,于是可以用Liquid中的 {{url}} 。
mode 为 merge,合并之前的信息作为最终的输出。当然也可以利用模板template以及Liquid来调用之前获取的对象。
这里再利用Liquid中的strip_html用法,将所有的html标签去除,最终得到的content就只剩包含\n的字符串了。(之前试了XPath Function里的normalize-space函数,发现所有文字都连一起了,丑死了emmm
最终得到如下的Options。
{
"expected_update_period_in_days": "2",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0",
"url": "{{url}}",
"type": "html",
"mode": "merge",
"extract": {
"content": {
"css": ".wp_articlecontent",
"value": "."
}
},
"template": {
"content": "{{ content | strip_html }}"
}
}将通知推送到微信
Crawler_AAO #3 WeChat Push
这里利用Server Chan提供的微信模板消息推送服务,之前也写过一篇:小想法 | 基于PushBear API实现微信消息推送。这次再来用一下呢。
现在 PushBear 一对多的推送需要绑定认证过的服务号了,但是个人的推送还是可以用的。
这次用的就是Huginn里的Post Agent啦。
method
这个Agent的method可以是get, post, put, patch, and delete,基本的都能实现。
Server Chan那边说是用GET,但好像POST也行。
post_url
填写Server Chan的API地址, https://sc.ftqq.com/{% credential YourServerChanAPI %}.send?
这里把API保存到了Credentials里,直接用Liquid模板调用就好了。
content_type
这里用form(application/x-www-form-urlencoded)。
payload
API接口有两个参数,标题text(必须),描述desp(可选),支持Markdown语法。
这里自己定义就好了啦~ 怎么开心怎么来嘻嘻嘻。
"payload": {
"text": "【{{title}}】",
"desp": "{{ url }}{% line_break %}{% line_break %}{{ content | replace: \"\n\", \"\n\n\" }}"
}要注意的是:如果直接在它的模板里修改参数信息,则**带有\的会自动转义为\\**!
因此直接写\n不可行,而要点击Toggle View然后直接写\n。或者也可以调用 Huginn 提供的方法 {% line_break %} 。
另一个问题,在Server Chan中\n\n才能换行,于是利用 Liquid 的 {{ content | replace: \"\n\", \"\n\n\" }} 把\n给替换成\n\n。(需要直接写,不能直接在参数的框里改。
还要注意保存后如果再次修改则\n又会自动变为\\n,注意留意。建议保存之前先Dry Run试试。
emit_events
如果设为true,则会返回一个Event,可以再加一个Agent来判断是否发送成功。
例如某次发送成功后得到的Event如下,其中的body部分为返回的数据。
{
"body": "{\"errno\":0,\"errmsg\":\"success\",\"dataset\":\"done\"}",
"status": 200,
"headers": {
"Server": "nginx",
"Date": "Tue, 10 Feb 2020 09:00:51 GMT",
"Content-Type": "text/html;charset=utf-8",
"Transfer-Encoding": "chunked",
"Connection": "keep-alive",
"Expires": "Thu, 01 Jan 1970 00:00:01 GMT",
"Cache-Control": "no-cache, must-revalidate",
"Pragma": "no-cache",
"Via": "100167",
"Set-Cookie": "PHPSESSID=xxxxxxxxxx; expires=Wed, 11-Feb-2020 09:00:51 GMT; path=/; domain=sc.ftqq.com; HttpOnly",
"Content-Length": 47
}
}将通知推送到Telegram Channel
Crawler_AAO #3 Telegram Channel Push
同样使用的是Post Agent。(看了一下,Telegram Agent好像不大灵活,而且还需要先有一个Event Formatting Agent,让Event中包含either a text, photo, audio, document or video key.)
昨天研究了好久Telegram Bot,看了看官方API文档,发现没有想象中的那么困难233333。
首先 @BotFather 注册一个TGBot,得到token。
这里没有设置Webhook,只需要用到sendMessage方法就好了。
post_url
URL为https://api.telegram.org/bot<token>/sendMessage,将<token>部分换成自己的Bot token,可以保存到Credentials里。
如https://api.telegram.org/bot123456:ABC-DEF1234ghIkl-zyx57W2v1u123ew11/sendMessage
可以先用 PostMan 测试一下。
别忘了bot……(是我了
method
POST or GET
content_type
- URL query string
- application/x-www-form-urlencoded
- application/json (except for uploading files)
- multipart/form-data (use to upload files)
payload
参数列表如下
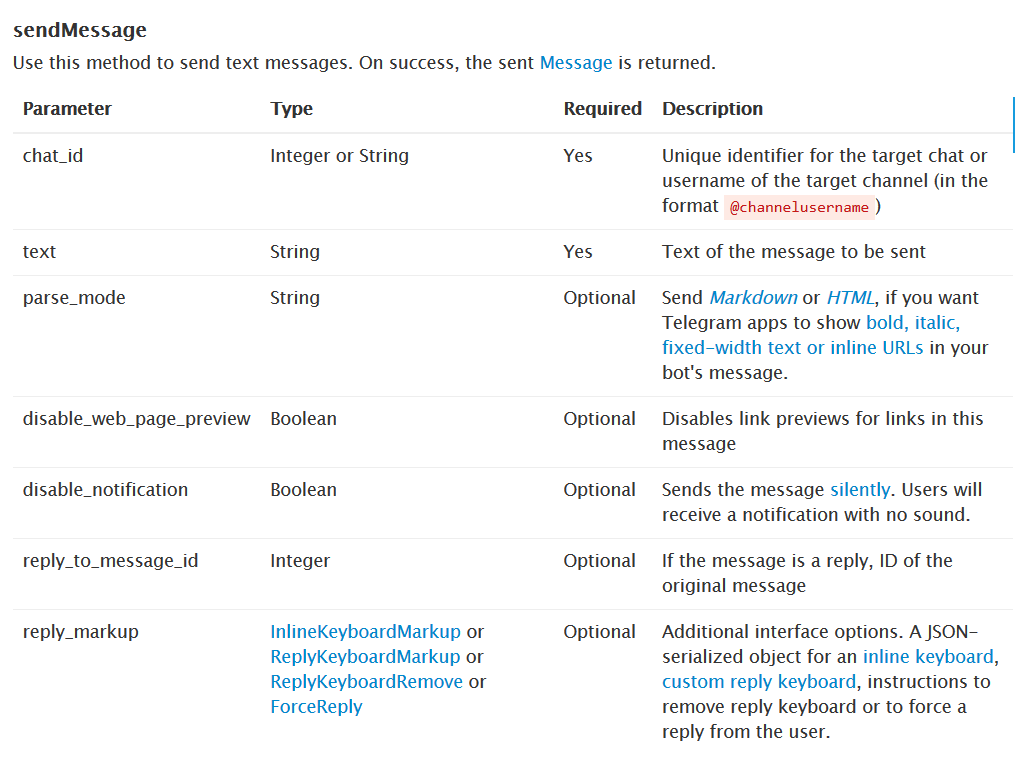
也可以使用Markdown语法。(还别说,真挺好
其实还有一个问题,我部署Huginn的服务器是在墙内的,于是还需要想办法转发出去。
具体自己想办法了啦。
(折腾了半天用 heroku 搭了一个自己凑合着用
小结
其实最初是想看看Huginn怎么用的,折腾过程中还去看了Liquid模板语法,XPath Functions用法。
推送到微信的前几天就弄好了,昨天想看看TG Bot怎么玩,于是研究了一下Bot API,顺便又写了个推送到TG Channel的。
最终的效果——
每隔一段时间,Huginn 就会派出一个Agent小兵,去看一看教务有没有新的通知公告。
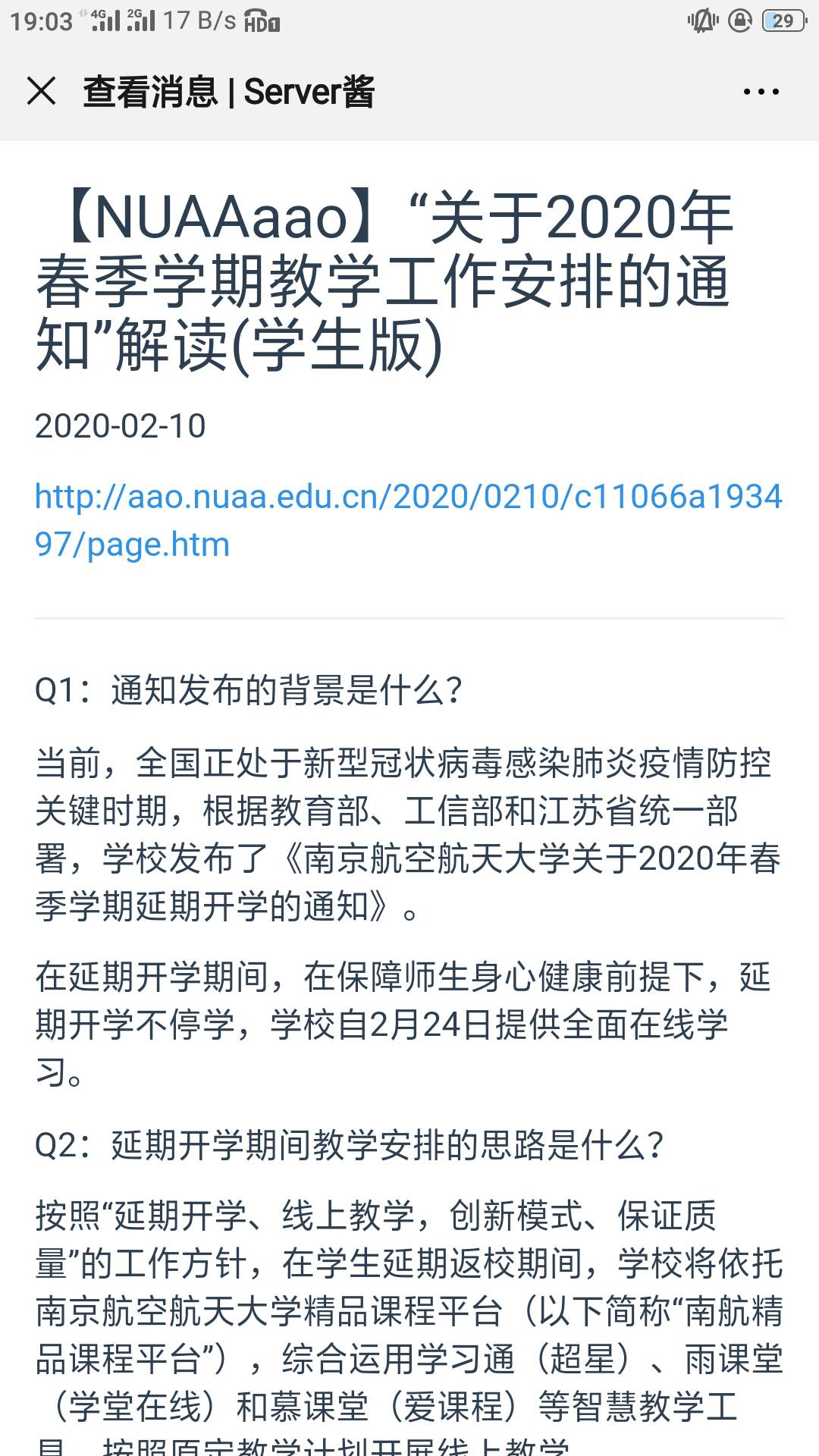
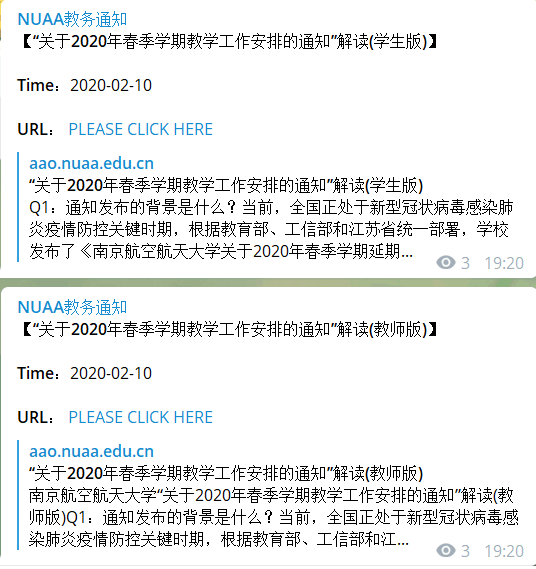
噢来了呀!Agent带回来了一个新的Event,快把它推给主人吧!
Ding~
微信来了一条新信息。
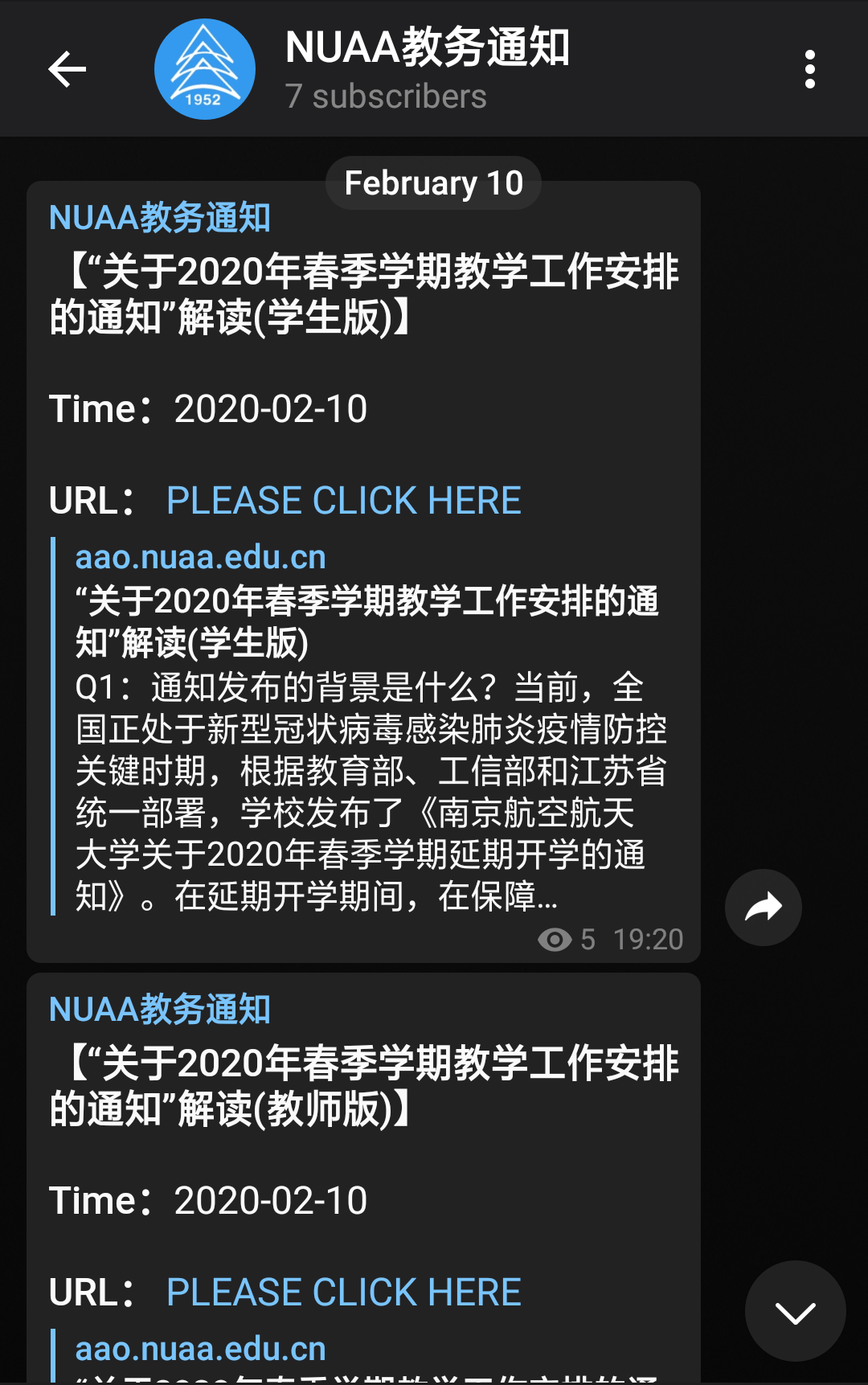
TG的Channel那边也来了。
嗯,这个感觉就很棒,朴实无华,且枯燥。(然而并没有钱
emmm 24号开始就要网上上课了。
以上内容仅供学习研究,请勿用于非法用途。
噢对了,TG Channel的邀请链接在这个域名里找嘻嘻嘻——
_tg_aaonotice.miaotony.xyz
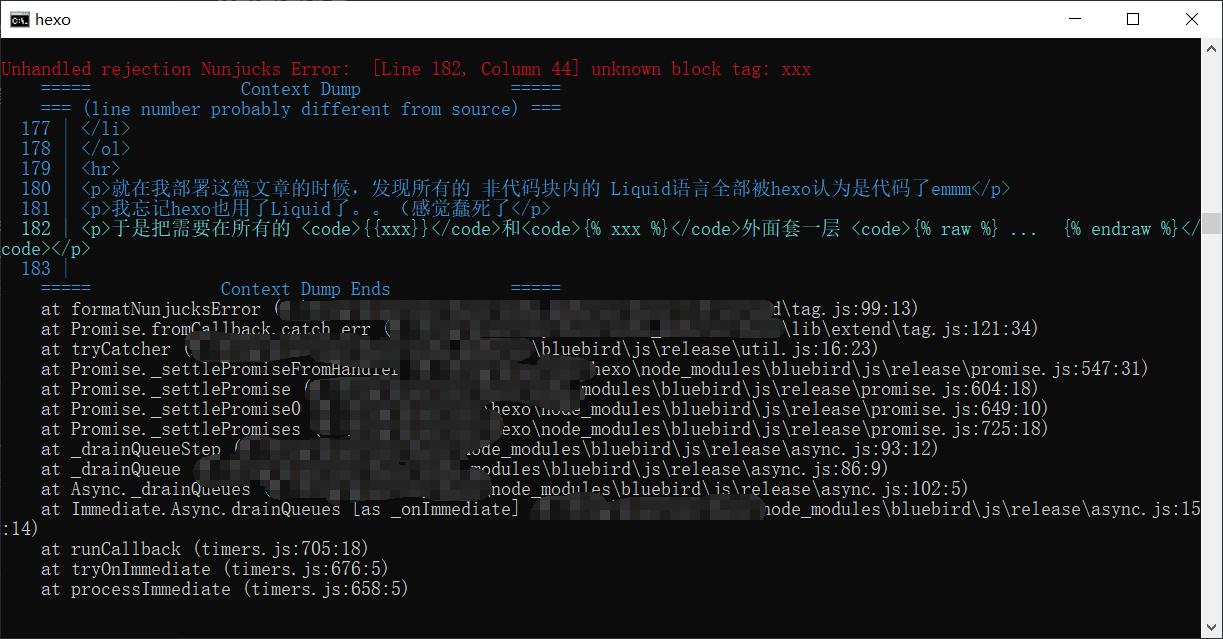
就在我部署这篇文章的时候,发现所有的 非代码块内的 Liquid语言全部被hexo认为是代码了emmm
我忘记hexo也用了Liquid了。。(感觉蠢死了
于是把需要在所有的 {{xxx}}和{% xxx %}外面套一层 {% raw %} ... {% endraw %}
如果要写上面这个raw,需要写两个(类似于转义)。