0x00 前言
众所周知,机器学习对于计算机的算力要求很高,而 GPU 中的并行计算能有效地提高计算效率。NVIDIA 家的 GPU 大都支持 CUDA(Compute Unified Device Architecture)平台,TensorFlow 等机器学习/深度学习框架大都以 CUDA 为基础实现了 GPU 加速计算。
CUDA ® is a parallel computing platform and programming model developed by NVIDIA for general computing on graphical processing units (GPUs). With CUDA, developers are able to dramatically speed up computing applications by harnessing the power of GPUs.
CUDA(Compute Unified Device Architecture,统一计算架构)是由NVIDIA所推出的一种集成技术,是该公司对于GPGPU的正式名称。透过这个技术,用户可利用NVIDIA的GeForce 8以后的GPU和较新的Quadro GPU进行计算。亦是首次可以利用GPU作为C-编译器的开发环境。
另外提一下 vGPU,这个概念好像是2018年提出来的,还算比较新的。考虑到有些程序需要在 Linux 环境下运行,而在 Windows 下一个选择是开一个虚拟机。之前还在想虚拟机里能不能用独立显卡,能否实现在虚拟机里调用 CUDA 进行计算。vGPU 的出现就提供了这一可能。
vGPU 即虚拟 GPU,可以为每个虚拟桌面提供 GPU 体验。NVIDIA 虚拟 GPU 软件使每台虚拟机都能像物理桌面一样利用 GPU。由于通常由 CPU 完成的工作已经转移到了 GPU,因此用户能够获得更好的体验,并且可以支持更多的用户。
其实按我的理解,简单来说就是对物理上的 GPU 做了虚拟化,这样在虚拟机上可以共享一个或多个 GPU。使用的时候就和平常用真实的 GPU 没有什么区别。感觉还是挺不错的,一定程度上有利于资源的合理利用嘛。不过具体的原理我也不清楚呢。(悄咪咪
更多关于 vGPU 的信息可以去官网了解一下。
其实之前配过 Windows 系统上的 GPU,成功实现了的。(然而不记得了)
然而上次配 CentOS 系统上的 GPU,有点问题折腾了好久一直都用不了,于是不知道怎么整就一直闲置着……
最近别人帮忙换了 Ubuntu 系统,重新配置了一下 GPU 资源,装好了显卡驱动。然后我折腾了一个下午,终于在 Ubuntu 16.04 系统上配置好了 TensorFlow 的 vGPU 环境,这里来做一下笔记啦。(不然过几个月甚至过几天就不记得了呢)
(什么时候成运维的了。。
唉,其实挺麻烦的,这里面也挺多坑的,特别是版本问题很容易导致配置失败。这里参考了挺多网上的资料还有前人分享的经验教训,以软件配置为主,大概包括下面几个步骤吧。
安装 Ubuntu 虚拟机
安装 NVIDIA 显卡驱动及授权
安装 CUDA Toolkit
安装 Anaconda3
安装 tensorflow-gpu 版本(包括了 cuDNN)
0x01 安装前准备
请确认要安装的各软件的版本之间是否匹配,如果不匹配很容易就配置失败了!
我这里的系统是 Ubuntu 16.04。
(Linux下)tensorflow-gpu 版本与 cuDNN 及 CUDA 版本关系如下,最新版本及其他系统请参考官方这里。
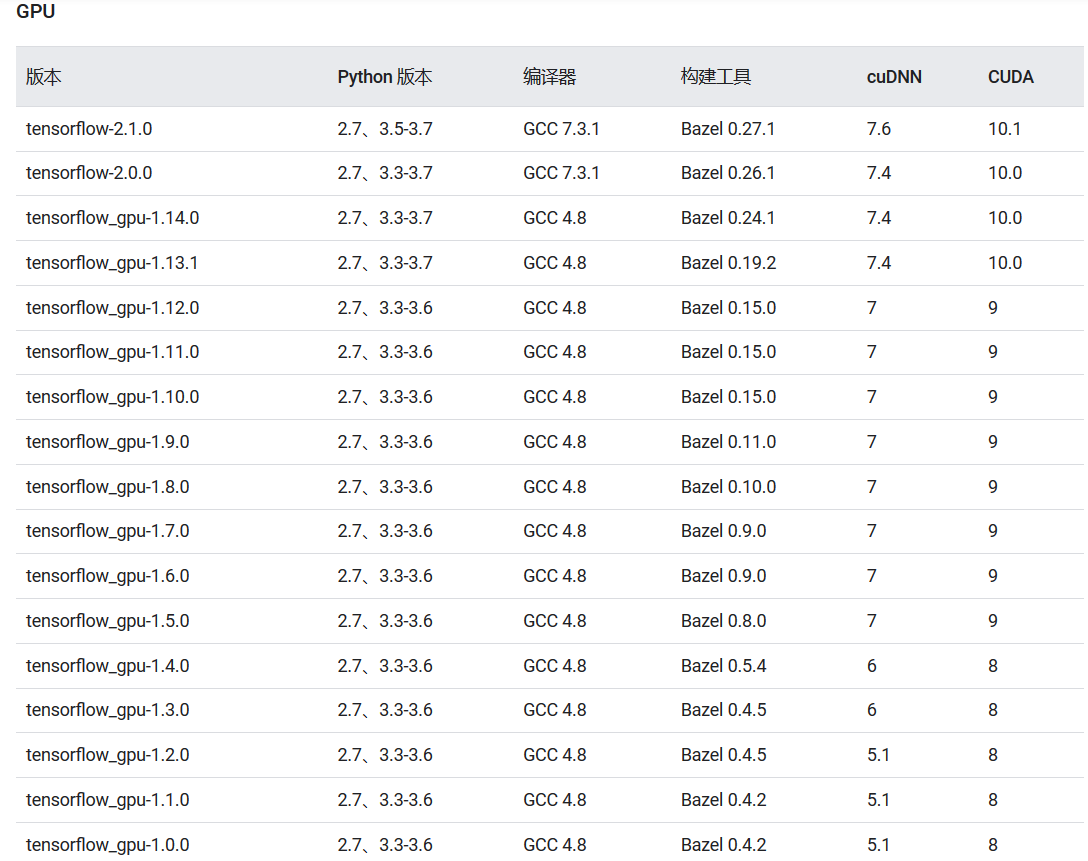
Tensorflow 2.x 版本挺新的,API 也改了不少,这里看1.x版本好了。
目前 Tensorflow 1.x 版本最新的是 1.15.0 了,上面这些是经过测试的构建配置,新版本的 CUDA 和 cuDNN 不保证一定能用,但低版本不行的。特别是 CUDA 和 cuDNN 版本要对应上。
CUDA Toolkit 与 显卡驱动之间的对应关系如下,最新版本请参考官方这里。
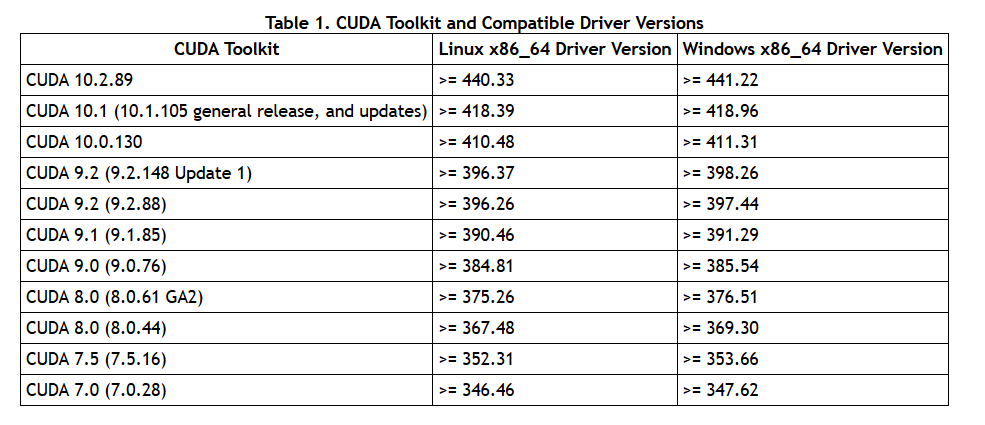
这里是 CUDA 工具包所要求的显卡驱动的最低版本。
例如 TensorFlow-gpu 1.13 以上版本需要 CUDA 10.0,显卡驱动至少要 410.48 以上这样。
0x02 安装 Ubuntu 虚拟机
这里是以服务器上安装为例的,我这里现成配好了的,大概就参考下面这一篇好了。
https://bbs.sangfor.com.cn/forum.php?mod=viewthread&tid=104141
0x03 安装 NVIDIA 显卡驱动及授权
这里别人帮配好了的,同样参考上面那一篇,这里记录一下吧,顺便借一下图。
0x03-1 安装显卡驱动
虚拟机新建一个文件夹,然后上传类似于 NVIDIA-Linux-x86_64-430.63-grid.run 的显卡驱动文件。
注意一下这个版本要满足 0x01 中的条件。

或者可以这样↓。
首先添加源。
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update检查可以安装的驱动版本,选择最合适的版本安装即可。
sudo apt install nvidia-driver-XXX安装显卡驱动的时候需要注意,先执行sudo init 3 然后在驱动文件目录下执行sudo sh 显卡驱动名 --no-opengl-files (加--no-opengl-files的目的是为了防止图形界面登录的时候循环输入密码的情况),然后按照提示执行下一步就可以。

显卡安装完成后进行检查,**执行nvidia-smi**,如果输出类似如下,则代表显卡安装成功。
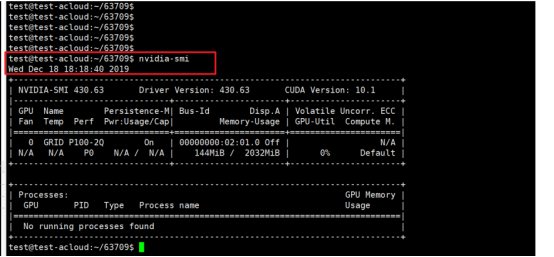
类似于下面这样的。(我这里显卡驱动版本为 440.56)
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.56 Driver Version: 440.56 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GRID P100D-2Q On | 00000000:02:00.0 Off | N/A |
| N/A N/A P0 N/A / N/A | 144MiB / 2032MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
0x03-2 显卡授权
下面进行显卡授权的配置。
如果使用的是切分显卡,那么授权一定是 vDWS 授权类型,此处需要提前先部署好 vGPU 授权服务器,授权服务器的部署,此处不再赘述。
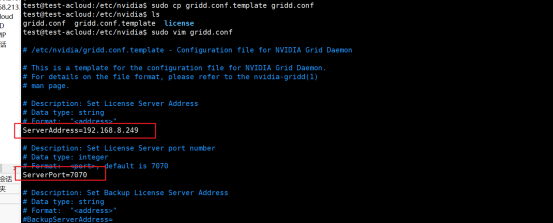
然后再虚拟机中配置授权信息,执行命令
cd /etc/nvidia,然后ls查看会有一个授权文件配置模板,然后执行命令sudo cp gridd.conf.template gridd.conf。

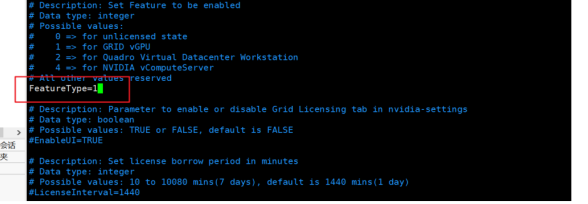
编辑授权信息,执行
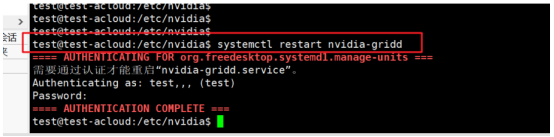
sudo vim gridd.conf,然后需要配置三个地方,也即授权服务器的地址、端口、以及授权类型,填写完成保存之后执行命令systemctl restart nvidia-gridd。

而后在授权服务器确认虚拟机是否已经获取到授权。
到这里为止,下面的步骤就和 vGPU 没有很大的关系了,就当物理机上的真实 GPU 使用就好了。
也就是说下面的步骤对于 Linux 下的 GPU 理论上都是通用的啦。
0x04 利用 Docker 快速启用 TensorFlow GPU 支持
这里打断一下,说一个快速启用 TensorFlow GPU 支持的方案。如果只是想体验一下,或者在 docker 中构建的话,可以参考一下,不需要后面的步骤就能快速启用了。
Docker 使用容器创建虚拟环境,以便将 TensorFlow 安装结果与系统的其余部分隔离开来。TensorFlow 程序在此虚拟环境中运行,该环境能够与其主机共享资源(访问目录、使用 GPU、连接到互联网等)。我们会针对每个版本测试 TensorFlow Docker 映像。
Docker 是在 Linux 上启用 TensorFlow GPU 支持的最简单方法,因为只需在主机上安装 NVIDIA® GPU 驱动程序,而不必安装 NVIDIA® CUDA® 工具包。
(来自官方 Docker 安装教程)
首先(在虚拟机上)安装 docker,而后需要**安装 NVIDIA Docker 支持**。
请通过
docker -v检查 Docker 版本。对于 19.03 之前的版本,您需要使用 nvidia-docker2 和--runtime=nvidia标记;对于 19.03 及之后的版本,您将需要使用nvidia-container-toolkit软件包和--gpus all标记。
注意:请确保已正确安装 Nvidia 显卡驱动,docker 版本>=19.03!
这样就不需要安装 CUDA toolkit 了。
目前最新的 docker 就是 19.03.8 版本,所以用nvidia-container-toolkit 软件包和 --gpus all 标记。
0x04-1 安装 nvidia-container-toolkit
(Ubuntu 16.04/18.04, Debian Jessie/Stretch/Buster)
# Add the package repositories
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker之后就可以测试一下能否在docker里调用显卡了。
#### Test nvidia-smi with the latest official CUDA image
docker run --gpus all nvidia/cuda:10.0-base nvidia-smi正常的话效果与 nvidia-smi效果相同。
下面这几个是指定特定显卡的。
# Start a GPU enabled container on two GPUs
docker run --gpus 2 nvidia/cuda:10.0-base nvidia-smi
# Starting a GPU enabled container on specific GPUs
docker run --gpus '"device=1,2"' nvidia/cuda:10.0-base nvidia-smi
docker run --gpus '"device=UUID-ABCDEF,1"' nvidia/cuda:10.0-base nvidia-smi
# Specifying a capability (graphics, compute, ...) for my container
# Note this is rarely if ever used this way
docker run --gpus all,capabilities=utility nvidia/cuda:10.0-base nvidia-smi0x04-2 拉取 tensorflow 官方镜像&运行代码
| 标记 | 说明 |
|---|---|
latest |
TensorFlow CPU 二进制映像的最新版本。(默认版本) |
nightly |
TensorFlow 映像的每夜版。(不稳定) |
version |
指定 TensorFlow 二进制映像的版本,例如:2.1.0 |
devel |
TensorFlow master 开发环境的每夜版。包含 TensorFlow 源代码。 |
每个基本标记都有用于添加或更改功能的变体:
| 标记变体 | 说明 |
|---|---|
tag-gpu |
支持 GPU 的指定标记版本。 |
tag-py3 |
支持 Python 3 的指定标记版本。 |
tag-jupyter |
带有 Jupyter 的指定标记版本(包含 TensorFlow 教程笔记本) |
下载并运行支持 GPU 的 TensorFlow 映像,而后运行这行代码测试一下。
docker run --gpus all -it --rm tensorflow/tensorflow:latest-gpu \
python -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"镜像大概2个G吧,拉取镜像挺久的……上面这个拉取的是最新版本的GPU镜像。可以通过上面这个测试一下是否安装成功。之后可以利用docker exec 重用容器。
使用最新的 TensorFlow GPU 映像在容器中启动
bashshell 会话:docker run --gpus all -it tensorflow/tensorflow:latest-gpu bash
要在容器内运行在主机上开发的 TensorFlow 程序,请装载主机目录并更改容器的工作目录 (-v hostDir:containerDir -w workDir):
docker run --gpus all -it --rm -v $PWD:/tmp -w /tmp tensorflow/tensorflow:latest-gpu python ./script.py要调用 GPU 的时候记得加上--gpus all标记呀!
0x05 安装 CUDA Toolkit
如果要直接(在虚拟机上)跑程序的话,需要装 CUDA 工具包。
这一步很关键,最开始我以为显卡上显示了 CUDA Version 就装好 CUDA 了,到最后一系列装完在 python 里测试 GPU 的时候报错说 tensorflow.python.framework.errors_impl.InternalError: CUDA runtime implicit initialization on GPU:0 failed. Status: all CUDA-capable devices are busy or unavailable
到谷歌查了挺多资料都没解决(上面这个问题可以参考这里有一些可能的解决方案),折腾了老半天才发现是 CUDA Toolkit 没装……还是在上一步中用 docker 测试才发现的呢。
执行 nvidia-smi 得到的CUDA Version应该是 CUDA Driver 的版本,这里要装的 CUDA Toolkit 对应的是 Runtime version 吧(猜的)。
根据 0x01 中的版本关系,以及上面 docker 中运行的 CUDA 版本,这里我用了 10.1.243 版本,可以在 CUDA Toolkit 10.1 update2 Archive 这里看下载地址。目前不推荐用最新的10.2版本,当然随着发展后续肯定会更新另说。
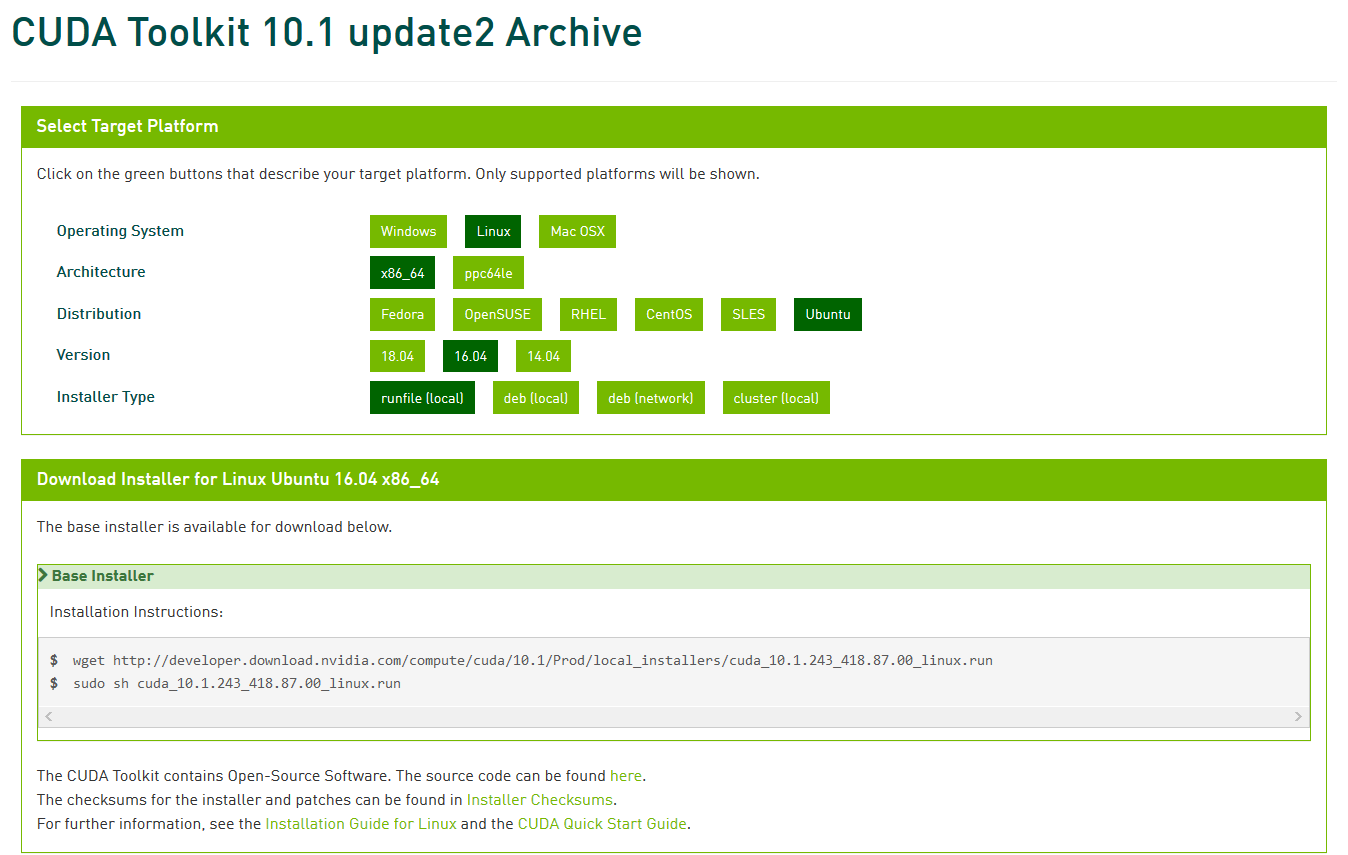
wget http://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.runsudo
sh cuda_10.1.243_418.87.00_linux.run这里安装界面挺有意思的,命令行里的折叠菜单,想不到吧!
注意一下:这里不要选 Driver 了,在Driver那里敲个回车把X去掉。因为你驱动已经装好了啦,而且比这个新。(截图的时候没有去掉懒得重新截了)
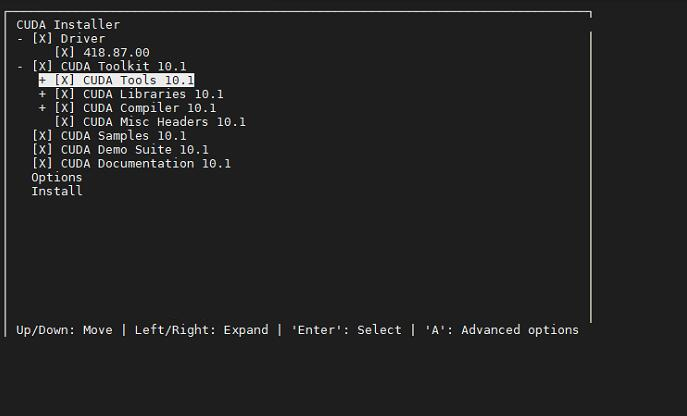
安装完之后要把路径加入到 PATH 里。
sudo vim ~/.bashrc在最后新增下面几行。
# CUDA config
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
export CUDA_HOME="/usr/local/cuda"
export PATH="/usr/local/cuda/bin:$PATH"使配置生效(或重启终端也行)。
source ~/.bashrc验证一下有没有安装成功。
miaotony@localhost:~# nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Sun_Jul_28_19:07:16_PDT_2019
Cuda compilation tools, release 10.1, V10.1.243如果上面安装时候装了实例的话,可以来测试一下。
cd /usr/local/cuda/samples/1_Utilities/deviceQuery/
sudo make
./deviceQuery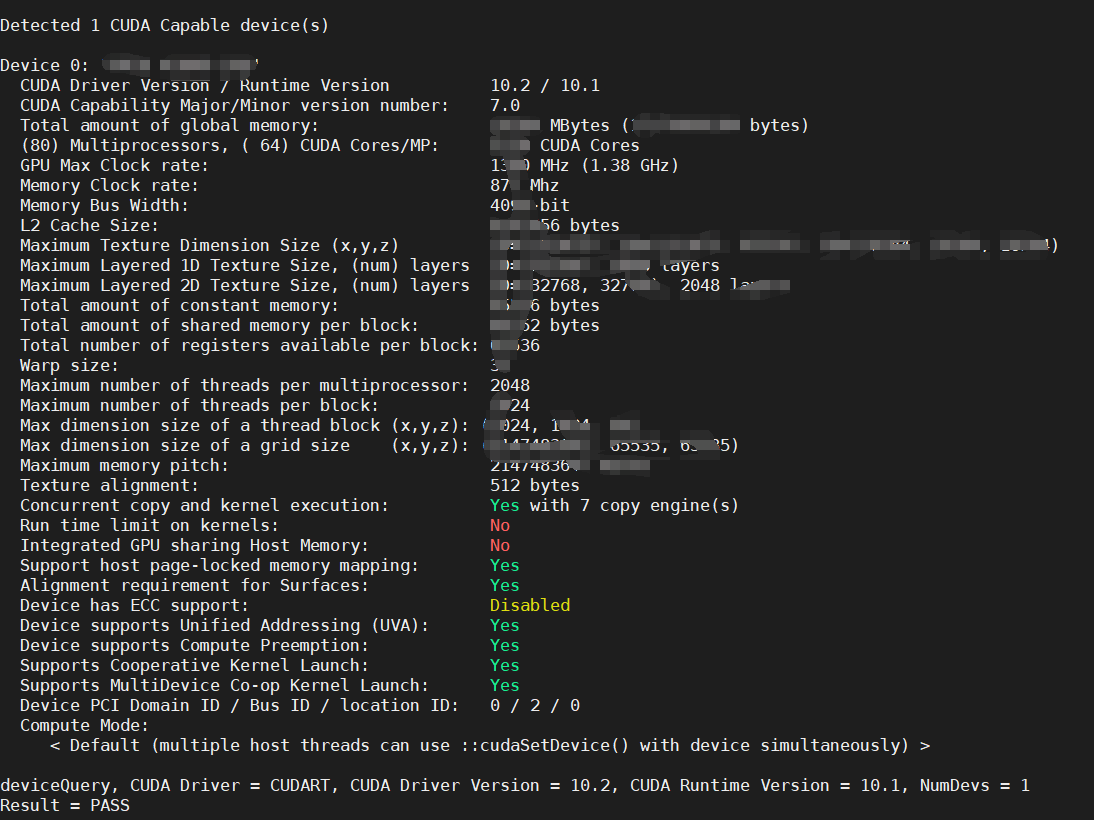
这里就显示出了显卡的各种参数,最后Result=PASS则说明安装成功了。
当然也可以试试别的例子,先编译再执行就好。
0x06 安装 Anaconda3
这里选择用 Anaconda 来安装,不仅因为有很多常用的科学计算库,而且后面会说 tensorflow-gpu 里还自带了满足版本要求的 cuDNN。(我也是这次才知道的呢
0x06-1 下载&安装
到官方这里下载 https://www.anaconda.com/products/individual。

2020.02版本 64-Bit (x86) Installer (522 MB)
按照提示安装,最好都输入yes,重启终端后会自动初始化 conda 的默认环境。
输入 conda --version,出现版本号则安装成功。
0x06-2 换源
众所周知官方的 conda 源速度比较慢,换清华 tuna 源吧。
(记得有段时间因为版权问题 tuna 镜像还中断过一阵子,后来放开了)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes0x07 安装 tensorflow-gpu (包括 cuDNN)
0x07-1 新建一个虚拟环境(可选的啦)
名为tensorflow,指定 python 版本为3.6。(这个看个人以及需求吧)
conda create -n tensorflow python=3.6可能需要确认就回车或者输入y完事。
0x07-2 安装 tensorflow-gpu
首先查一下当前环境下支持的版本。
conda search tensorflow-gpu注意一下驱动的版本问题,对于新的tf版本,驱动可能不支持。
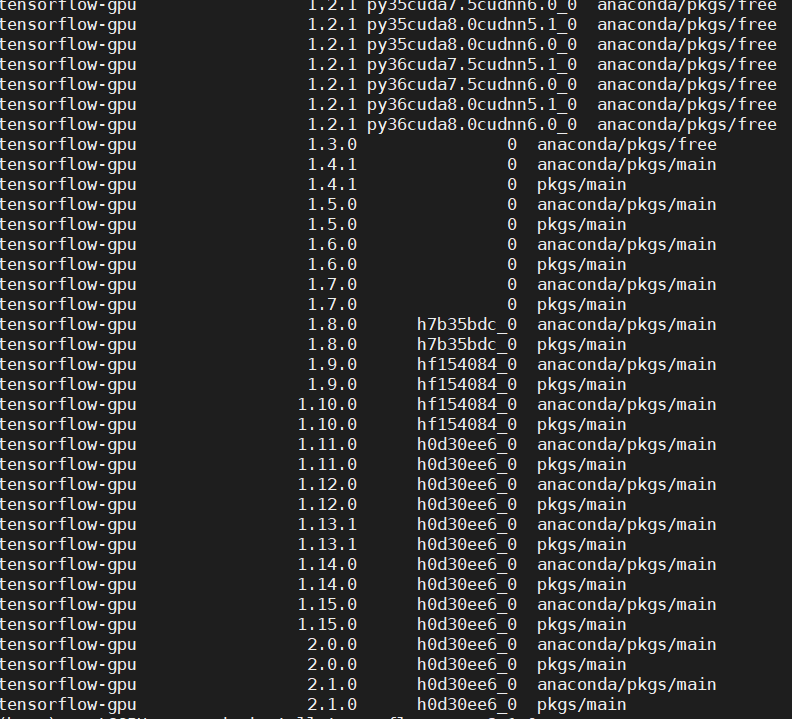
比如装1.15.0版本。
conda install tensorflow-gpu==1.15.0大概六七百MB的亚子,网络不是很稳定,大概率需要重试几次才行。
0x07-3 验证安装
安装完成后,进入python试一试呗。
import tensorflow as tf
print(tf.test.is_gpu_available())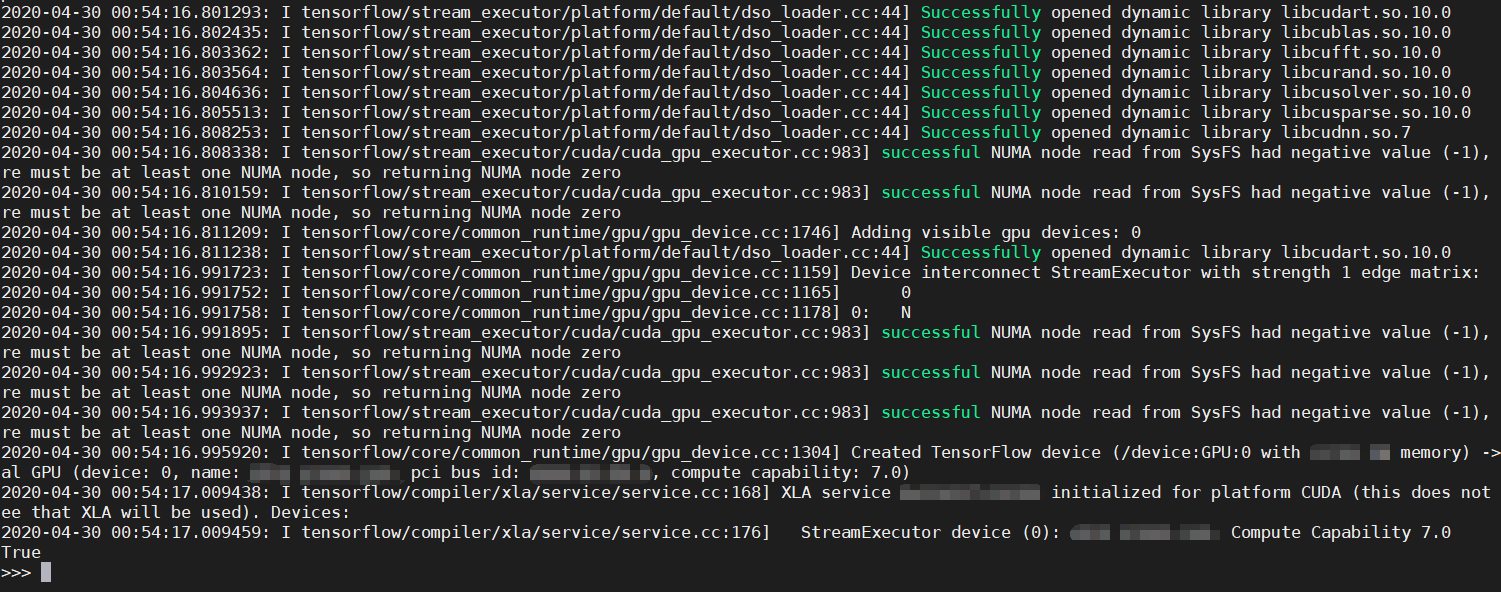
显示为True则表示以上安装成功了!
(tf 2.x 的话这个方法已经 deprecated 了,建议用tf.config.list_physical_devices('GPU') 方法。tf 1.x 无此用法。
WARNING: tensorflow:From <stdin>:1: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Usetf.config.list_physical_devices('GPU')instead.
也可以运行一个程序,然后另外再开一个终端,利用 nvidia-smi 查看显卡情况。
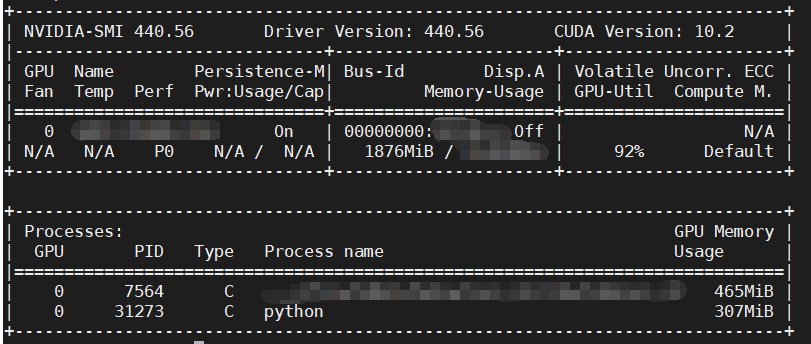
在 Processes 里看到运行的任务就成功了呀!
哇好耶!!!
终于搞定了!!!
之后你就可以愉快地炼丹啦!
0x08 小结
其实主要就是这几个步骤:
- 安装 Ubuntu 虚拟机
- 安装 NVIDIA 显卡驱动及授权
- 安装 CUDA Toolkit
- 安装 Anaconda3
- 安装 tensorflow-gpu 版本(包括了 cuDNN)
或者
- 安装 Ubuntu 虚拟机
- 安装 NVIDIA 显卡驱动及授权
- 安装 Docker nvidia-container-toolkit
- 拉取 tensorflow-gpu 镜像
其实过程挺麻烦的,而且遇到了不少坑,比如我这次的一部分经历……
显卡驱动装了,
nvidia-smi看没问题,还有个 CUDA Version 就以为有 CUDA 了。
装好 anaconda,然后用conda install tensorflow-gpu,这里面附带了 cuDNN。
然后测试 GPU 的时候给我报tensorflow.python.framework.errors_impl.InternalError: CUDA runtime implicit initialization on GPU:0 failed. Status: all CUDA-capable devices are busy or unavailable
这个错误。。
谷歌搜了老半天没搞懂,然后去装了 NVIDIA Container Toolkit,拉了个 tf 的 Docker 镜像跑,发现是没问题的。
最后想到是不是 CUDA 没装,于是看了 tf 镜像用的 CUDA 版本是10.1.243,去官网找来装上。
再回来到 conda 环境里测试,终于好了。。
特别是觉得马上要完事了,在验证 GPU 时候就发现报错了那种时候,很绝望不是吗。
不过一步一步来还是可以成功安装的,哇是有点成就感 23333.
机器学习/深度学习有空慢慢学呢(
呜,感觉莫名奇妙成运维的了,嘤嘤嘤不要。
((溜了溜了喵


